首页 > 极客资料 博客日记
数据结构 - 图
2024-11-02 03:00:03极客资料围观14次
今天我们开始学习目前学习到的最难最复杂的数据结构图。
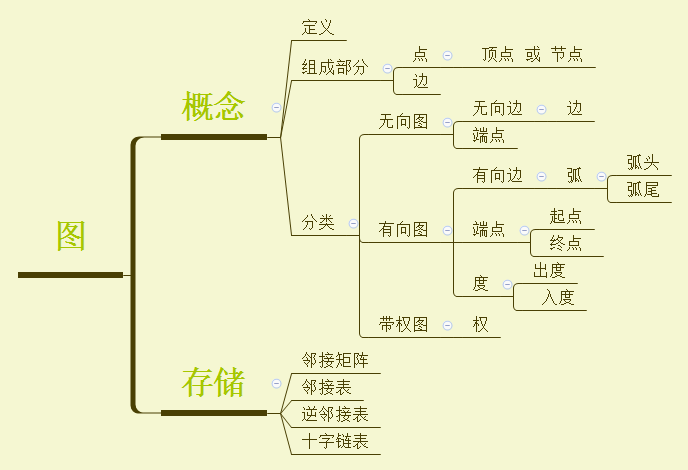
简单回顾一下之前学习的数据结构,数组、单链表、队列等线性表中数据元素是一对一关系,而树结构中数据元素是一对多关系,而图结构中数据元素则是多对多关系,任何两个数据元素之间都有可能有关系,由此可见图结构的复杂程度。
希望通过这篇文章可以让大家很轻松的了解和学习图结构并快速入门,把一些晦涩难懂概念通过合理的组织归类使其简单明了,再配合一些图例说明,希望可以使大家茅塞顿开。
01、基础概念
1、定义
图是一个二元组G=(V(G),E(G))。其中V(G)是非空集,称为点集,对于V中的每个元素,我们称其为顶点或节点,简称点;E(G)为V(G)各节点之间边的集合,称为边集。
常用G=(V,E)表示图。
2、组成部分
上面的定义可能较为抽象,我们也可以从另一个角度来理解图,即图的内部结构,图由哪些要素组成的——点与边。简单来说图就是由若干个点以及连接两点的边构成的图形,而上面的定义也只是在说所有的点和所有的边组成图,这样是不是就很容易理解了。
其中点可以代表某种事物,而边可表示两个事物之间的关系,这样我们就可以把一些实际问题转为图,然后使用软件解决问题。
3、分类
我们可以根据边是否有方向,是否带权,简单的将图分类为无向图、有向图、带权图,当然还有其他类型的图,现阶段我们就不过多介绍了,容易把自己搞晕。
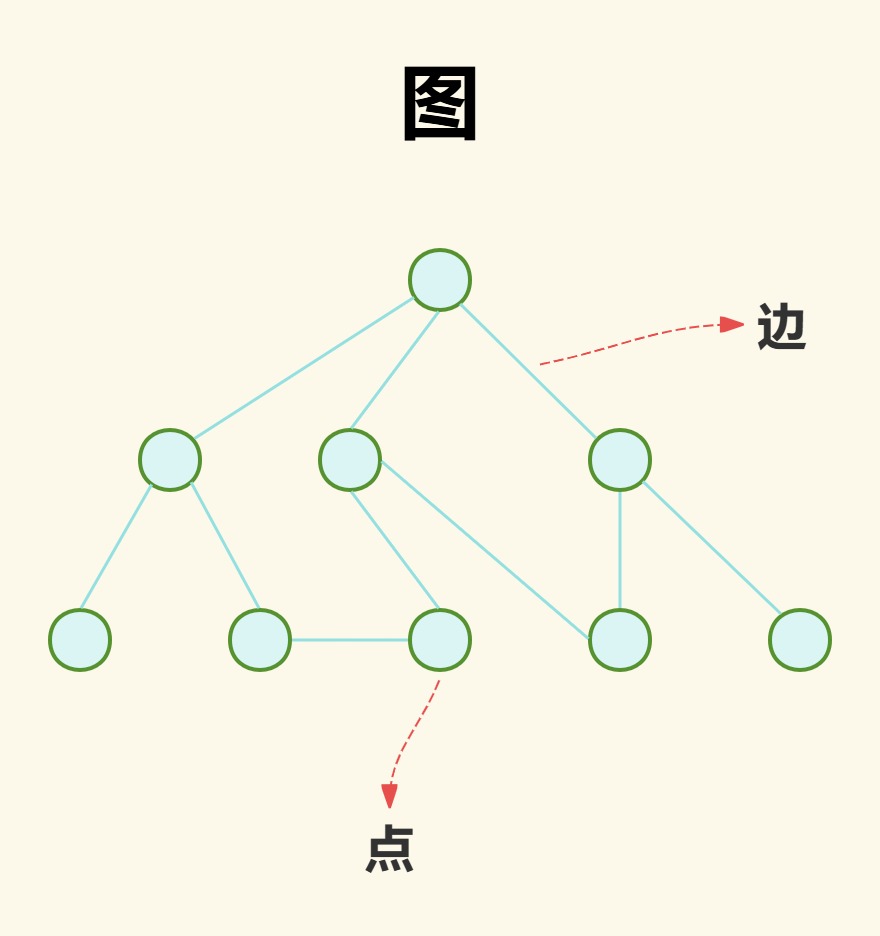
(1)无向图
无向图顾名思义就是边没有方向,即两个点之间没有方向,没有顺序之分,这样的边叫作无向边,也简称边。其中点也叫作端点。
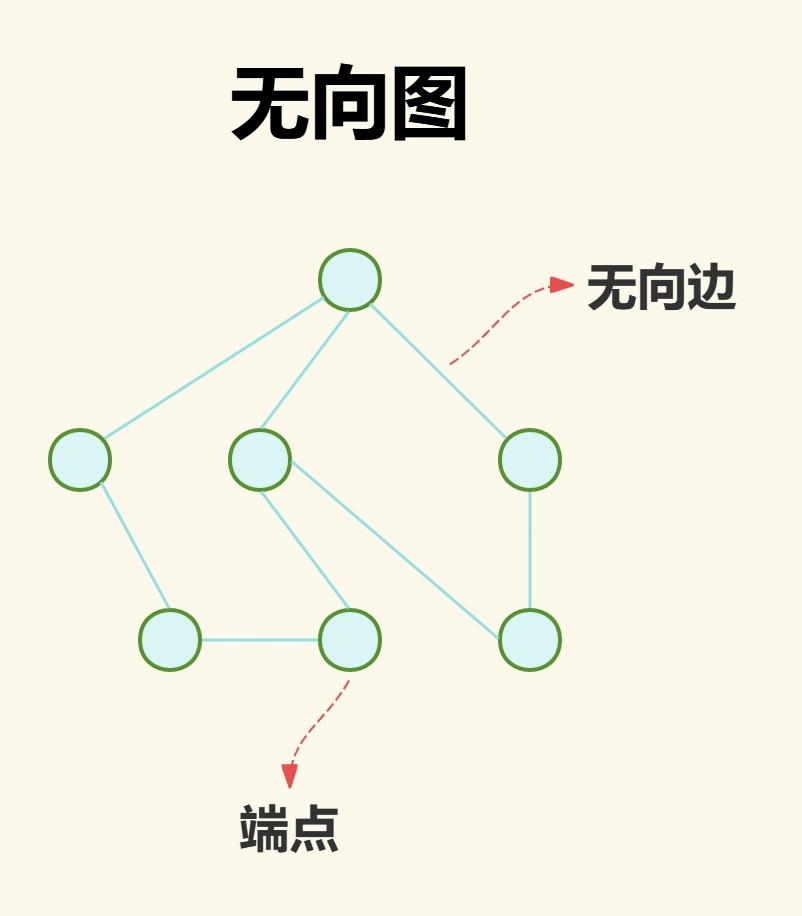
(2)有向图
有向图则指边有方向,也就代表边所连接的两点有顺序之分,其中一个为起点,则另一个则为终点,而这样的边就叫作有向边或弧。起点和终点也叫端点。
其中同一个点既可以是起点,也可以是终点。
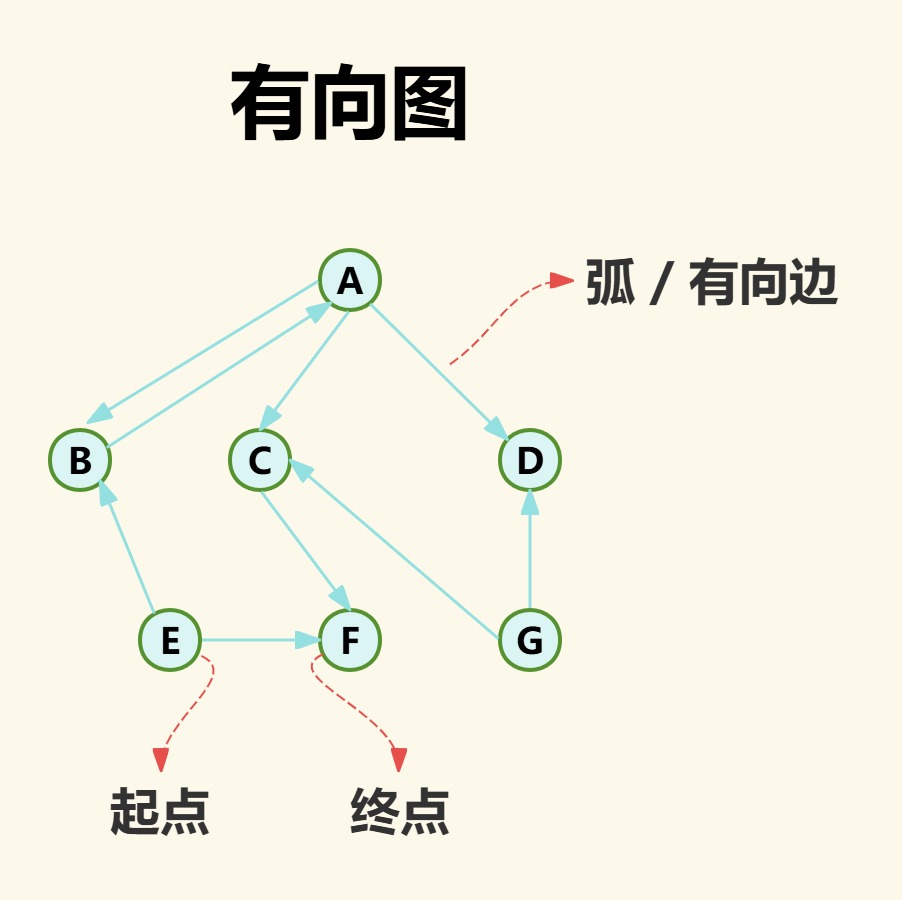
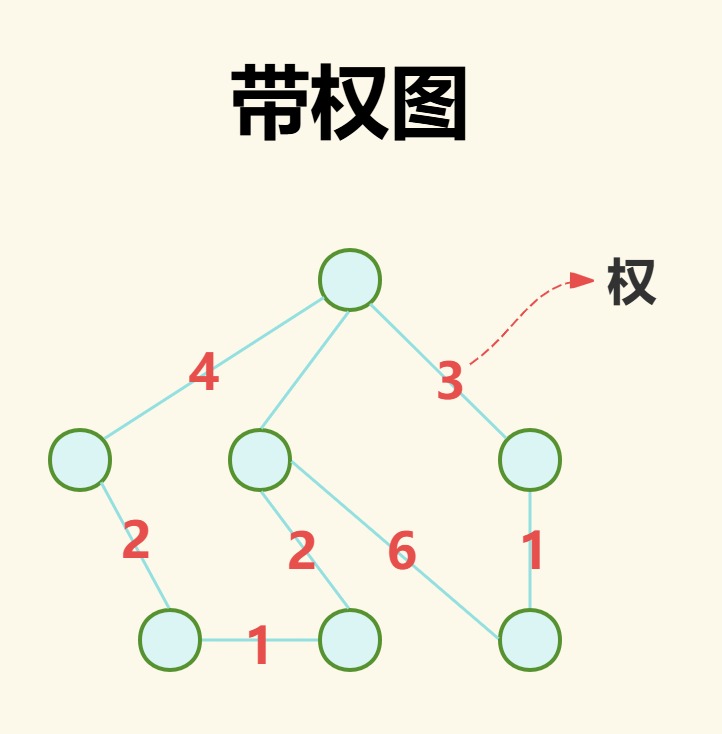
对于任何图,与一个点关联的所有边数称为该点的度。而对于有向图来说,以一个点为起点的边数称为该的点出度,以一个点为终点的边数称为该点的入度。
如上图点A的出度为3,入度1。
(3)带权图
带权图指每个边都带有一个权重,代表边连接的两点关系的强弱、远近。同时权只是代表边的权重,并不代表边的方向,因此无论无边图还是有边图都可以是带权图。
02、存储方式
了解了图的基本知识以后,带来了一个新的问题,这么复杂的结构我们要怎么存储下来呢?
下面我们就来介绍几种常用的存储方式邻接矩阵、邻接表、逆邻接表、十字链表。
1、邻接矩阵
邻接矩阵就是用一个二维数组来存储任意两点之间的关系,其中行列索引表示点,而行列索引所在的位置的值表示两点关系,其中两点关系可以用以下数值表示:
(1)0:表示两点之间没有边;
(2)1:表示两点之间有边;
(3)权值:表示两点之间边的权值;
如果图存在n个点,则可以用n x n的二维数组来表示图,下面我们来看看常见图的表示方式。
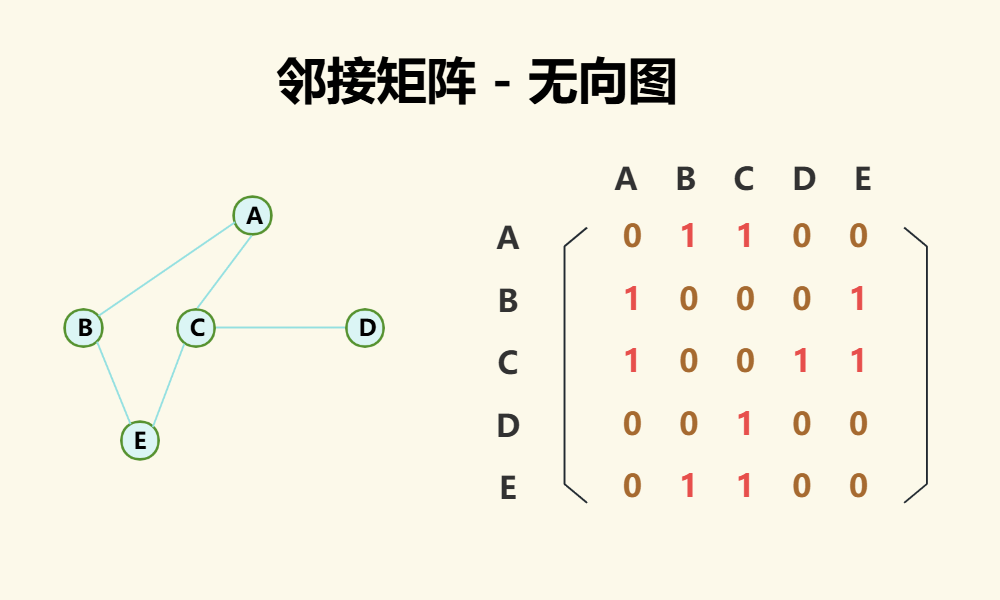
(1)无向图
对于无向图,如果点A与点B有边,则[A,B]与[B,A]都为1,否则都为0,因此无向图的邻接矩阵是对称的,如下图:
(2)有向图
对于有向图,则可以通过把行索引当作边的起点,把列当作边的终点,来表示方向,比如[A,B]为1,而[B,A]为0,如下图:
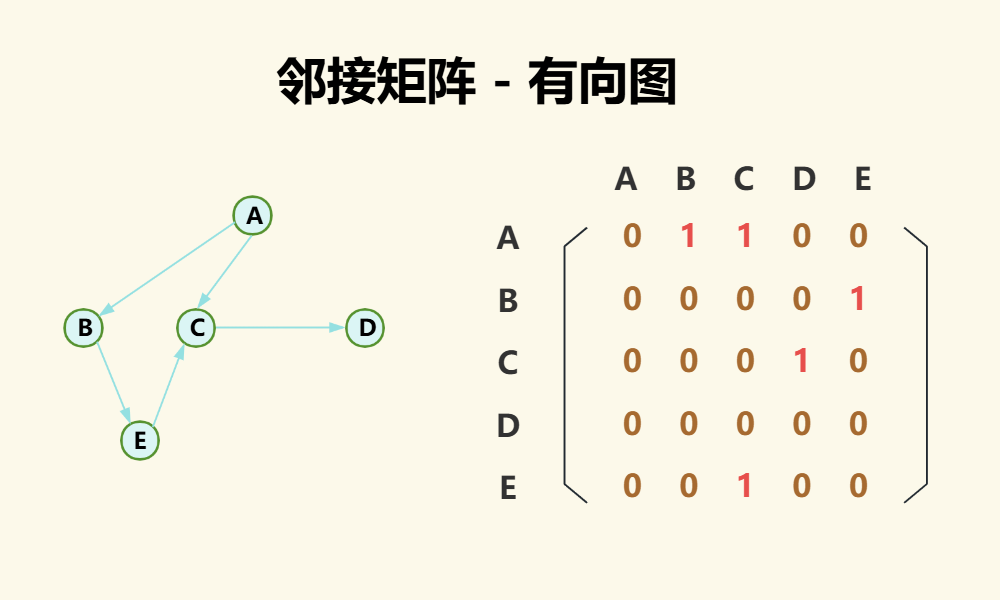
对于有向图,我们可以发现关于点的度有以下特性:
点的出度就是第i行元素之和;
点的入度就是第i列元素之和;
点的度就是第i行元素之和 + 第i列元素之和;
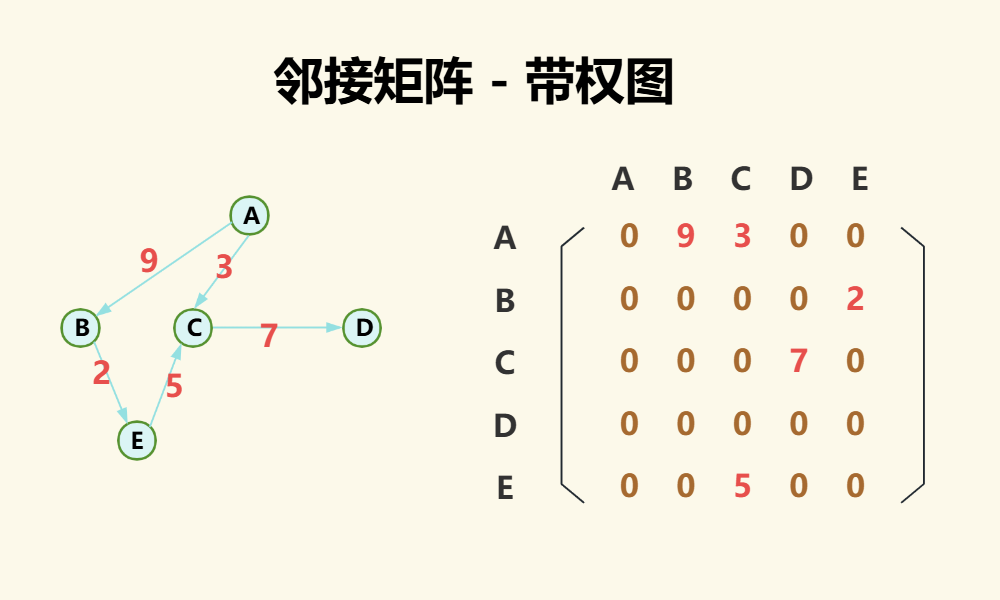
(3)带权图
对于带权图,本质上和无向图与有向图相同,只是存储的值有所差别,如果两点之间有边则直接存权值,如果两点之间无边则存一个特殊值(如0、无穷),如果可以保证权值中不存在0,可以用0,否则要选一个其他特殊值,如下图:
总结
优点:
(1)简单直观:实现简单,易于理解,尤其适合小型图。
(2)快速查找:便于判断两点之间是否有边,以及各点的度。
缺点:
(1)空间浪费:空间复杂度高为O(n^2),对于稀疏图,许多元素为零,造成空间浪费。
(2)不易扩展:不便于插入和删除点,需要更新整个矩阵,时间复杂度高为O(n)。
2、邻接表
对于邻接矩阵空间浪费以及不易扩展的问题,发展出了另一种链式存储方式——「邻接表」。
邻接表的存储思想和前面章节介绍的散列的链式存储很像。首先我们用一个数组存储所有的点,而每个点元素又作为单链表头,其后继节点则存储与头节点相邻的点元素。
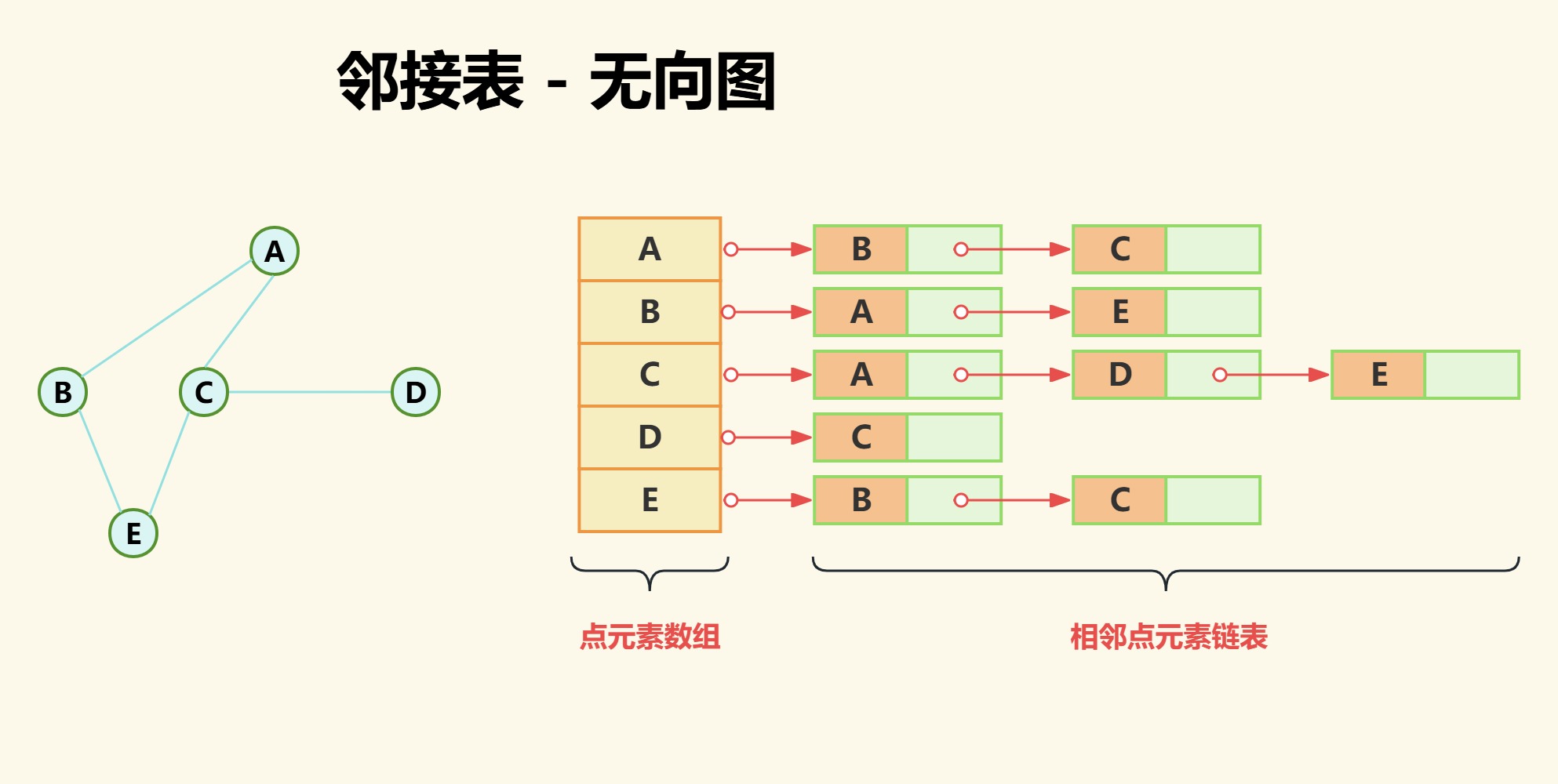
(1)无向图
如下图,图中所有点都存储在数组中,而与其相邻的点存储在其后面的链表中。
点A相邻的点为点B和点C;
点C相邻的点为点A、点D和点E;
点D相邻的点为点C;
(2)有向图
与无向图不同的是有向图链表中存储的不是所有相邻的点,而是存储有方向的点,即以数组中的点为起的终点元素。
点A为起点的终点为点B和点C;
点B为起点的终点为点E;
点D为起点的终点不存在;
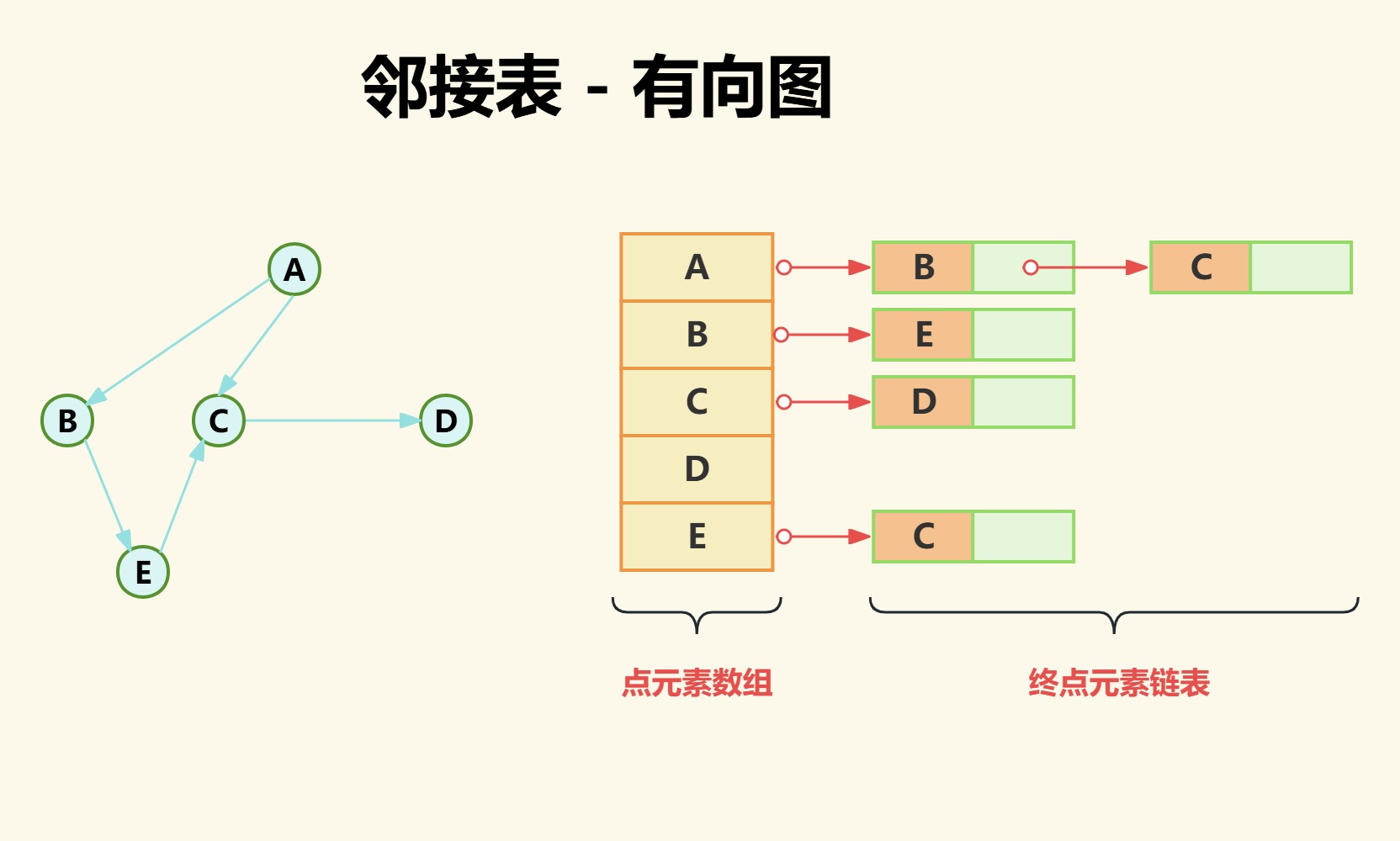
通过上图可以发现,邻接表对于有向图可以很直观的表示出某个点的出度,但是对于入度获取就很麻烦。
(3)带权图
带权图与无向图和有向图相比,只需要在元素中多加一个权重属性即可。
总结
优点:
(1)节省空间:时间复杂度相对较低为O(m+n),m为点数量,n为边数量,对于稀疏图存储效率更高;
(2)操作灵活:插入和删除点操作方便,时间复杂度为O(1);
(3)出度易取:对于有向图获取某个点的出度非常方便,只需要找到这个点所在的数组元素位置,然后获取其链表中的元素个数即可;
缺点:
(1)不便查找:判断两点之间是否有边的时间复杂度为O(V), 其中V 是该点的相邻点数量;
(2)入度难算:对于有向图点的入度的计算难度较大,时间复杂度为 O(E),其中E是图中的边的数量;
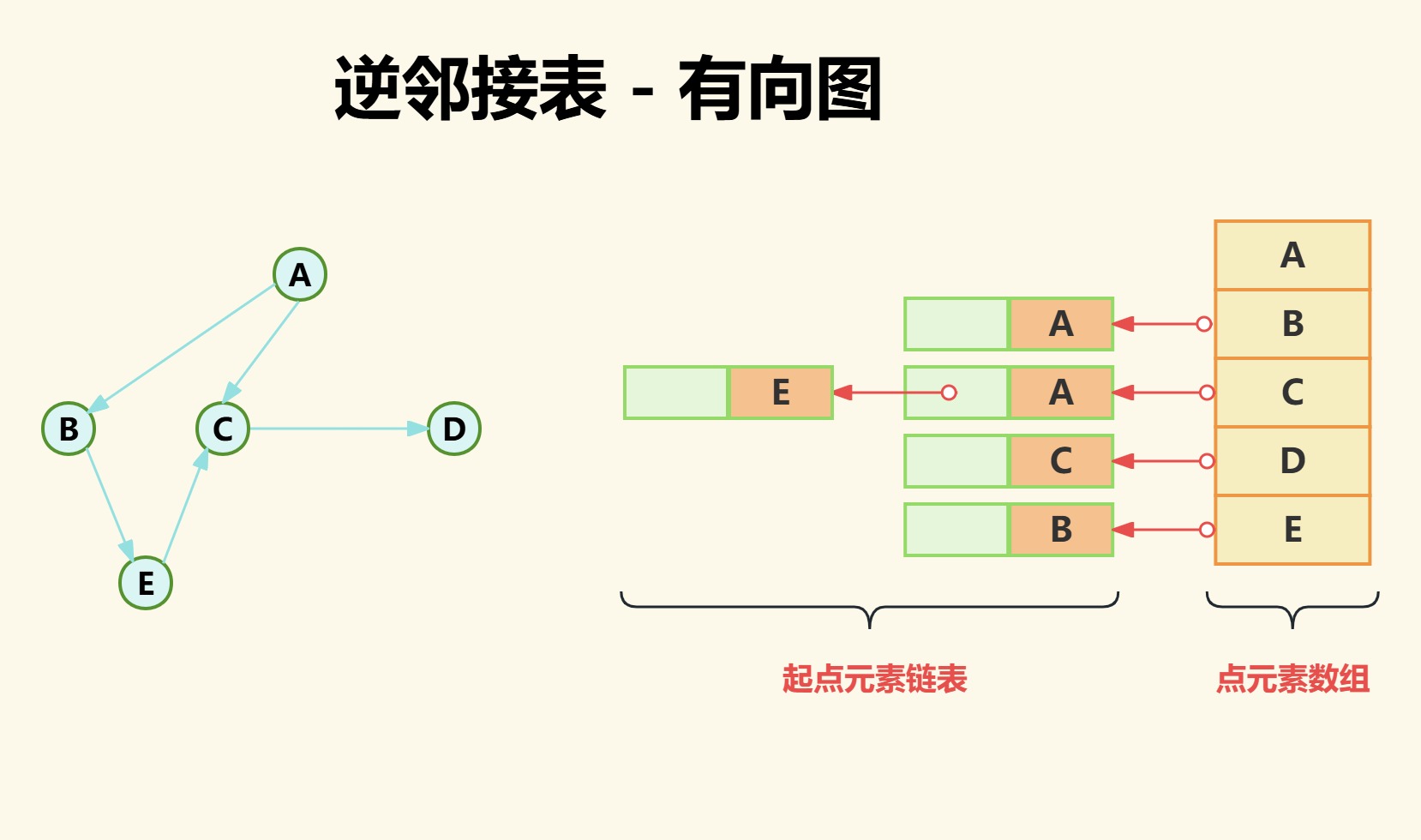
3、逆邻接表
逆邻接表从名字上就可以看出来和邻接表是逆的关系,这个逆就体现在入度和出度上。我们知道邻接表计算出度容易,计算入度难,而逆邻接表恰恰相反是计算入度容易,计算出度难。
如下图数组中存储点元素,而链表中存储的是以数组中的点为终点的起点元素。
点A为终点的起点不存在;
点B为终点的起点为点A;
点D为终点的起点为点A和点E;
总结
与邻接表差异在于在存储的方向正好相反,所以入度和出度计算难度正好相反,而其他则完全一样。
4、十字链表
邻接表出度计算容易,逆邻接表入度计算容易,那么有没有一种结构同时计算出度入度都容易呢?答案就是十字链表。
十字链表是邻接表和逆邻接表的结合体,每个点的边通过双向链表存储,同时记录了边的出度和入度。
下面我们详细讲解一下十字链表是怎么得到的。
(1)合并逆邻接表与邻接表
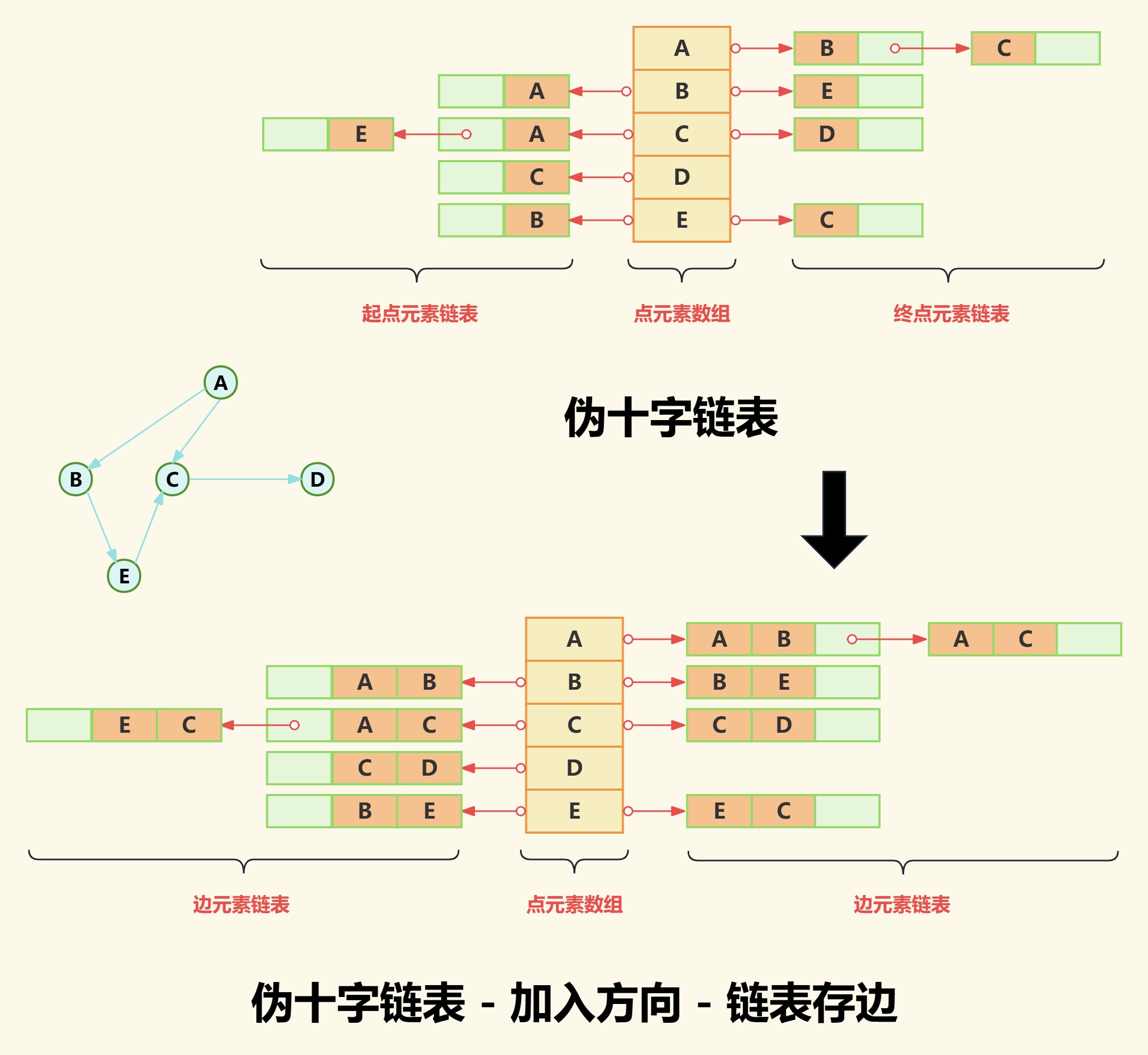
如下图我们之间把逆邻接表和邻接表拼接到一起,得到一个伪十字链表。
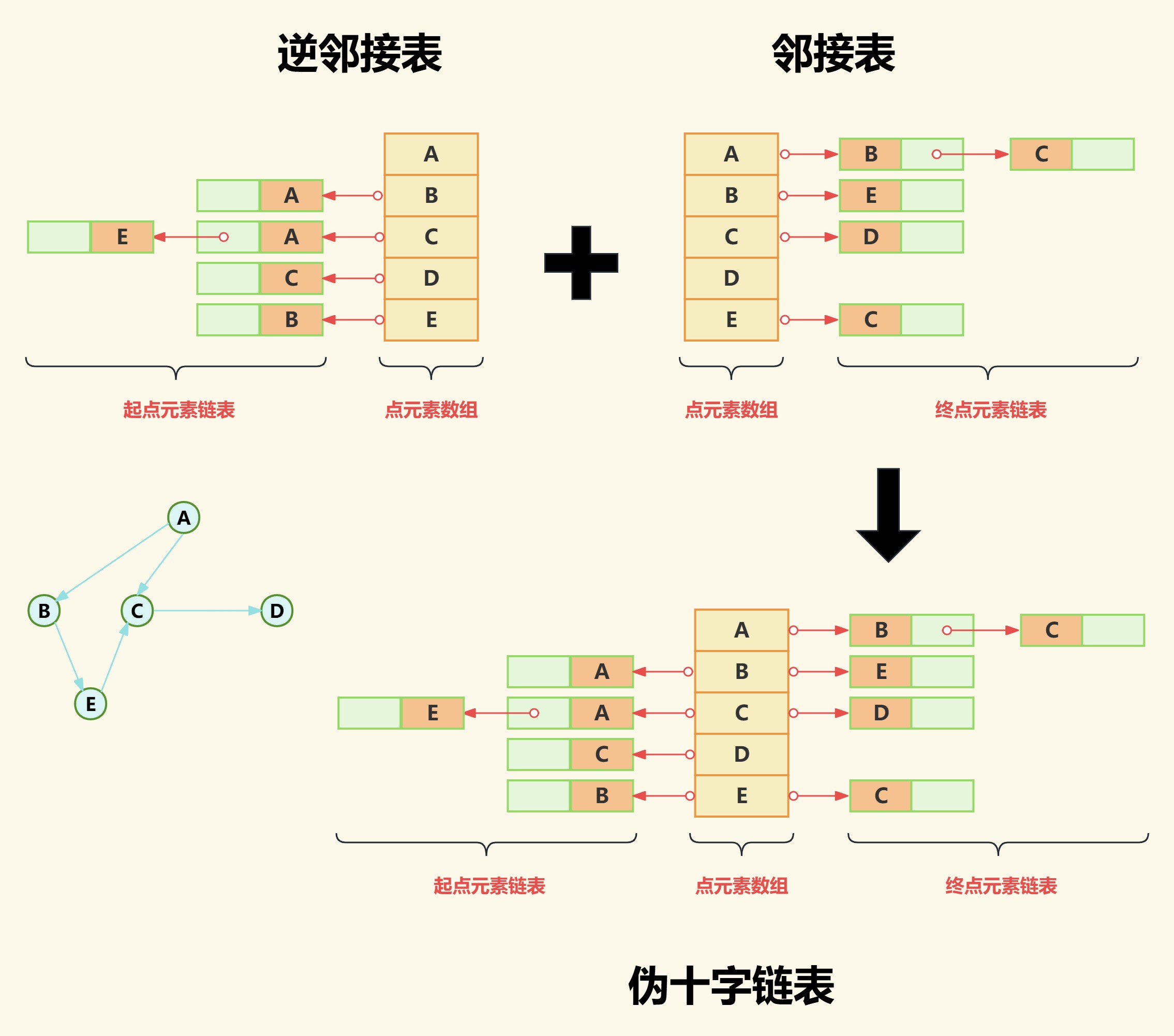
之所以称这个结合体为伪十字链表,是因为它虽然同时存储了边的两个方向,解决了出度入度计算问题,但是也引发了新的问题——存储效率低。
从上图不难看出链表中存在严重的重复存储的问题。要解决这个问题,我们先梳理一下我们得到的伪十字链表结构。
(2)链表由存点改存边
首先数组存储所有点,左侧链表存储起点元素集合,右侧链表存储终点元素集合;然后我们想为什么需要两条链表呢?因为一条链表就代表一个方向;
那第一步我们是否可以先解决方向的问题呢?而目前的结构节点只有一个点的信息,显然没有方向性,因此我们需要把链表节点改造成包含两个点的结构即起点和终点,这也意味着链表由原来存储点元素变为存储边元素。
原来点A出度链表存储点B和点C,现在改为存储[A->B]边和[A->C]边。
原来点B入度链表存储点A,现在改为存储[A->B]边。
如下图:
(3)删除重复元素
到这里就有条件解决重复的元素的问题了,比如上面链表中有两个[A->B]边,如果我们想把点B入度链表中[A->B]边删除,那么我们必须要有一个途径使得点B的入度链表可以和点A的出度链表中[A->B]边链接上。
首先数组元素结构应该至少包含:数据域|入边头节点指针|出边头节点指针;
然后链表节点元素结构应该至少包含:边起点下标|边终点下标|下一个入边节点指针域|下一个出边节点指针域;
下面我们进行去除重复元素,首先表里下出度链表结构,移除现有入度链表,其中入度链表中的元素指向到出度链表中,最后结果如下图:
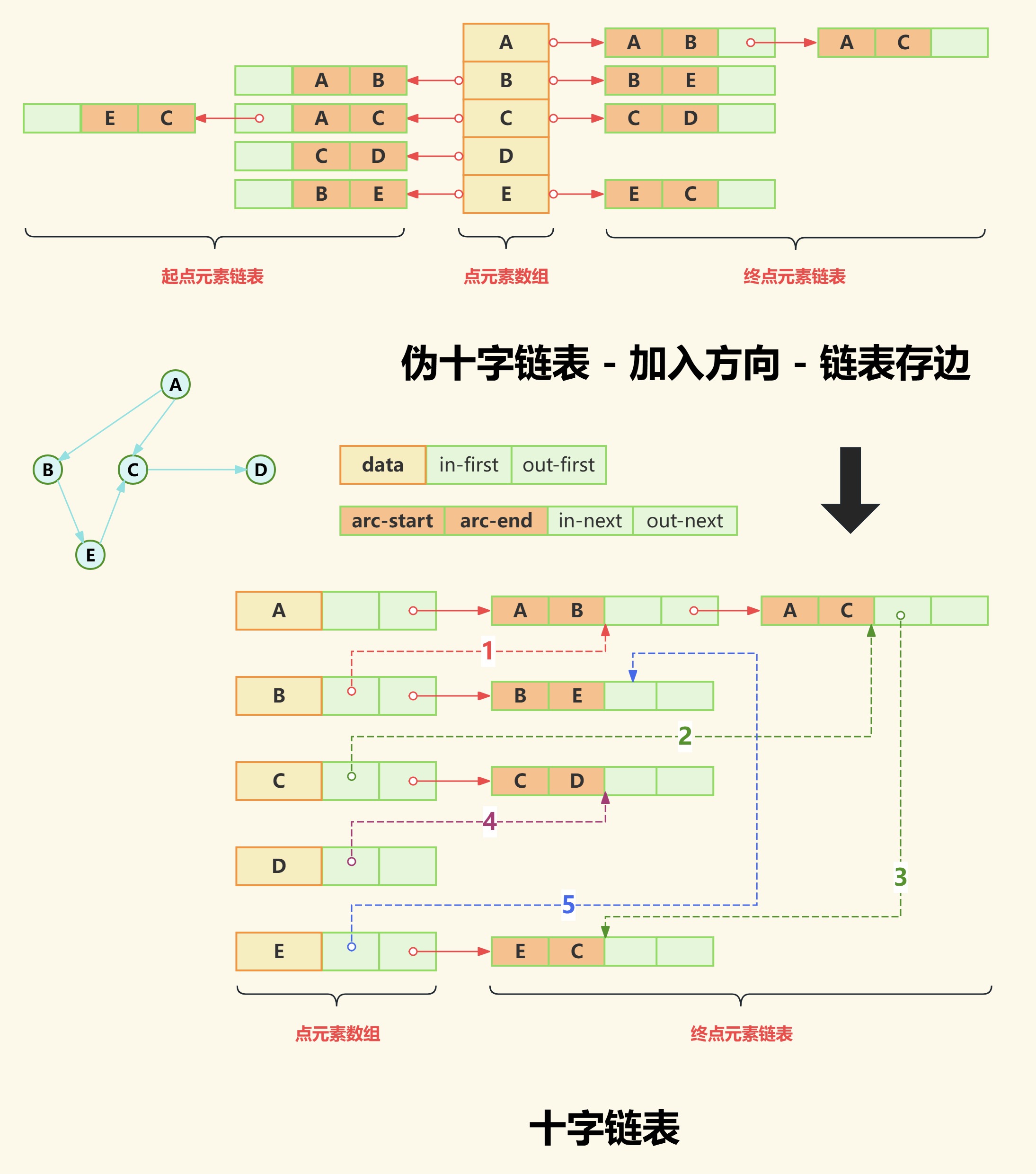
如上图红色实线箭头表示出度链表,而彩色虚线箭头表示入度链表。
点A为终点的边不存在,点A为起点的边为 [A->B]边和[A->C]边;
点B为终点的边为[A->B]边(即红色1号虚线),点B为起点的边为 [B->E]边;
点C为终点的边为[A->C]边(即绿色2号虚线)和[E->C]边(即绿色3号虚线),点C为起点的边为[C->D]边;
总结
优点:
(1)高效存储,适合复杂的有向图,支持快速遍历;
(2)快速计算出度入度;
缺点:
(1)实现复杂,维护难度高;
注:测试方法代码以及示例源码都已经上传至代码库,有兴趣的可以看看。https://gitee.com/hugogoos/Planner
标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
