首页 > 极客资料 博客日记
Diffuision Policy + RL -------个人博客_ZSY_20241101
2024-11-01 23:00:03极客资料围观13次
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, Shuran Song
原论文链接
投在了IJRR上
点击:原作者论文思路讲解
1. PPO背景引入
这里简要交代PPO的算法原理及思想过程





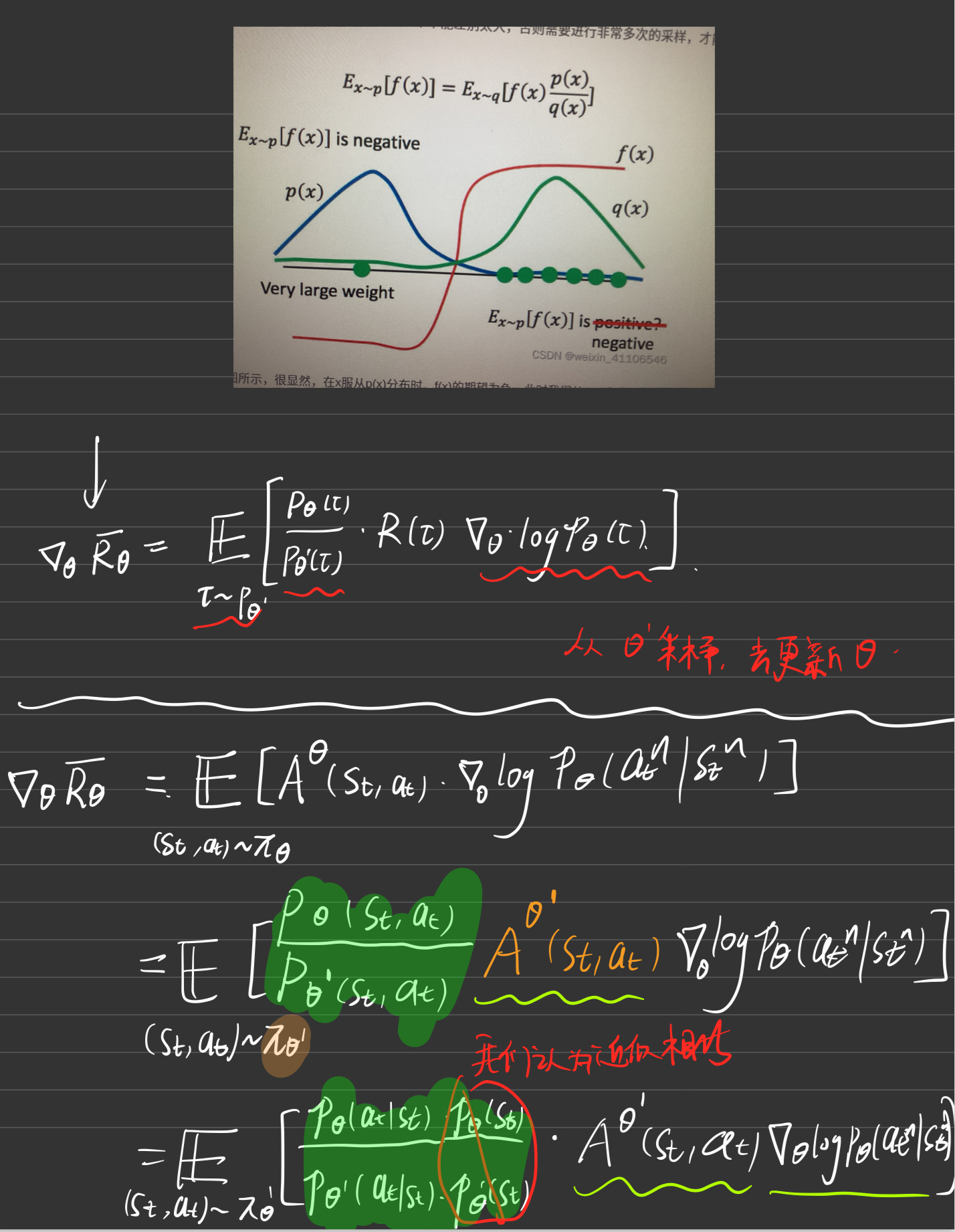
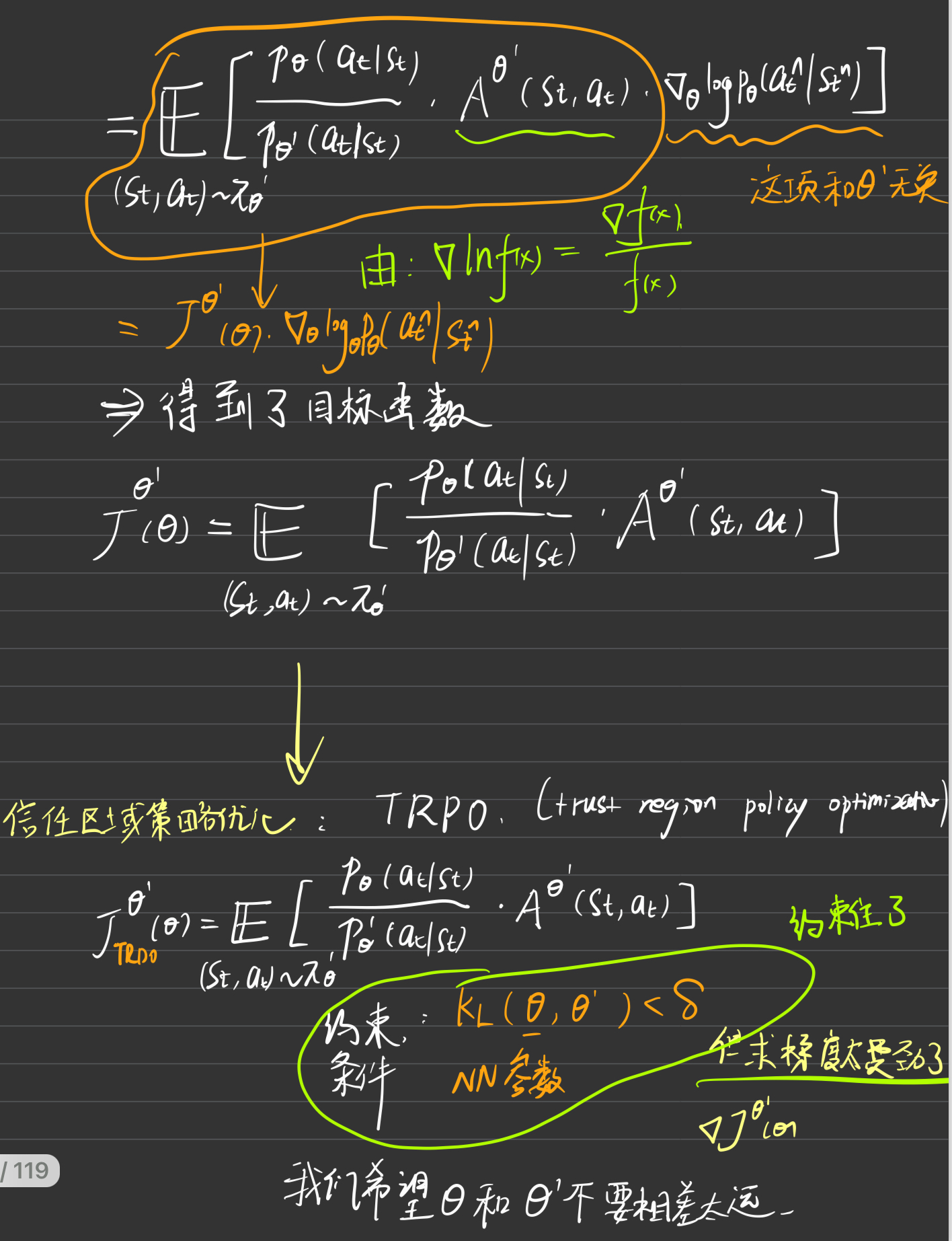

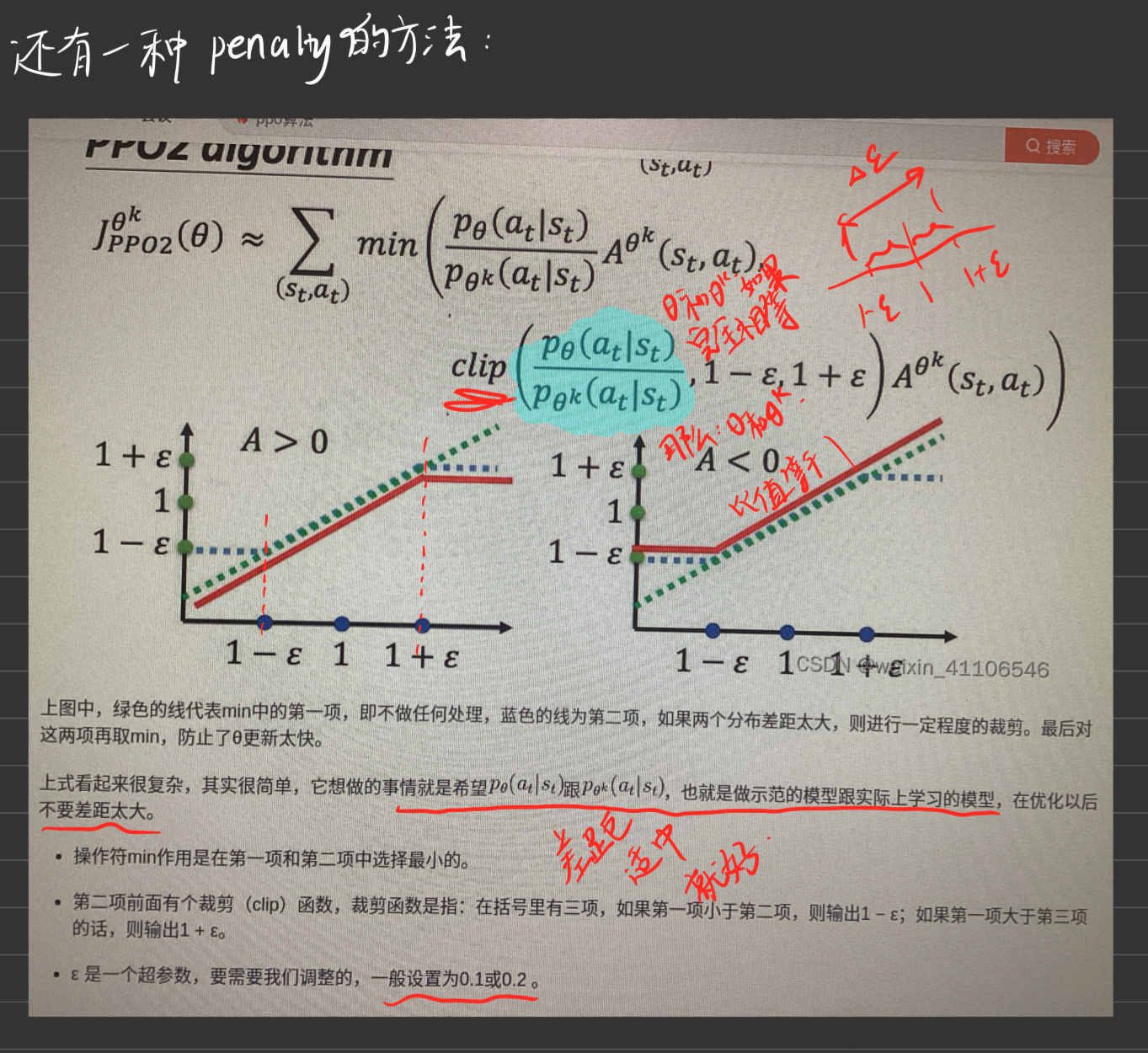
好到这里就是PPO的基本思想和RL的前期铺垫工作
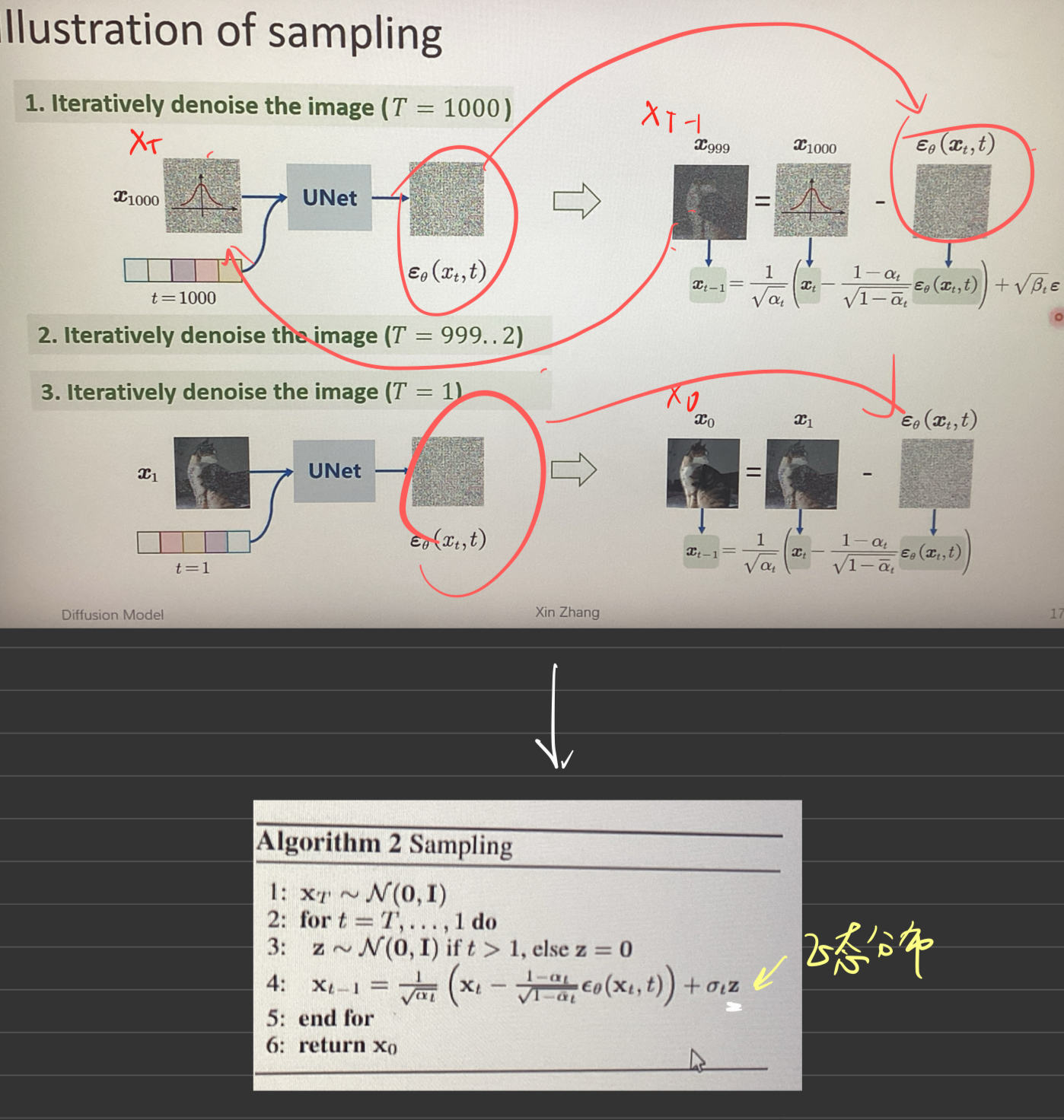
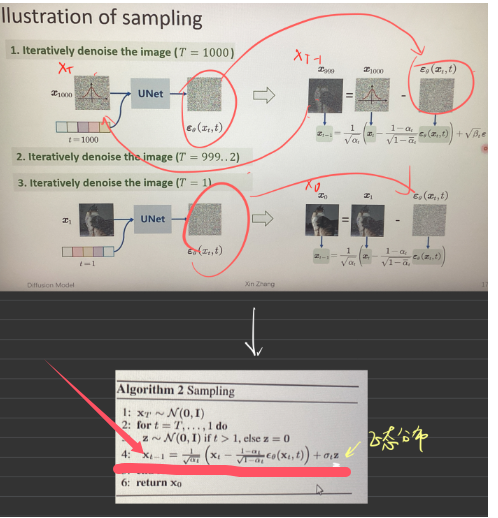
2. Diffusion Model回顾(DDPM)
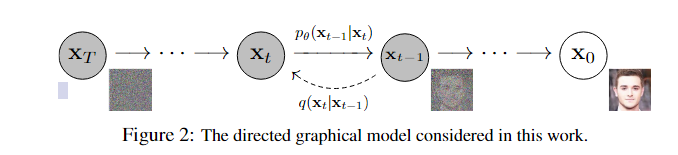

训练过程

采样过程
3. Diffusion Policy
(1)什么是Diffusion Policy
1.首先Diffusion,它是一种生成方法,如今图像生成领域的成就基本都是基于Diffusion方法,比如常听的Stable Diffusion和Midjourney。
2.其次Policy,它是机器学习算法用来驱动机器人的核心组成部分,它的输入是各种感知信息(比如相机拍到的视频,还有机器人各个关节的位置),而输出的是机器人要执行的动作。
3.简单理解,Diffusion Policy就是应用Diffusion这种方法生成机器人动作的一种Policy。


(2)铺垫1 --Planning with Diffusion for Flexible Behavior Synthesis (Diffuser)
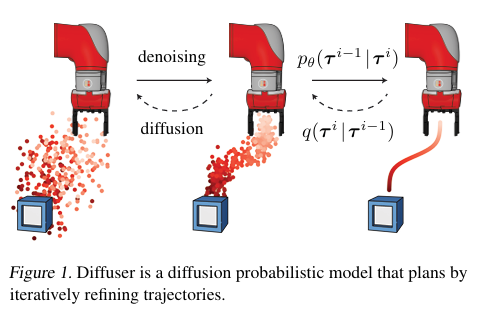
scoop 意味着有人在你的想法之前发表了类似的想法
Diffuser (offline)
具体来说,如果有一个包含各式各样轨迹 (trajectories) 的数据集 ,离线强化学习的目标便是从轨迹中挖掘构造出一个性能优秀的智能体 (agent) ,希望它能够直接部署至环境并获得不错的收益。
原论文将数据集每一条轨迹(trajectory)进行拼凑,就像下面这样:

表达为如下的二维数组,后续的算法设计就是在这样定义的轨迹表示上进行优化。
那么它的模型架构是怎样的?
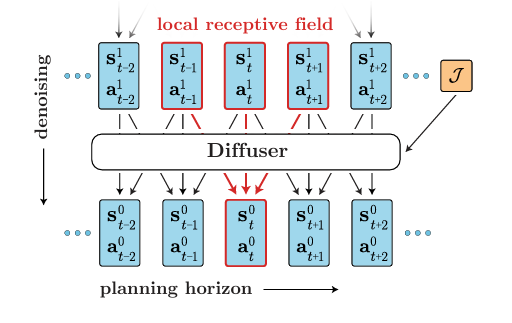
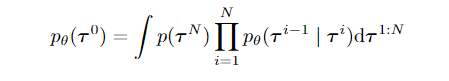



算法思想:其中J是用来进行预测累计轨迹回报的函数,这个函数可以使用神经网络来进行拟合,这样他的训练就是一个回归问题,用来回归每一个可能的ti的累计回报。


(3)铺垫2 --FiLM
一种特征层面的线性调节方式,在视觉推理(visual reasoning)任务中有很好的效果,可以用于特征合并,例如处理模型的多输入问题。

4.公式推导
论文中,首先非常简明扼要的交代了diffusion算法的一条公式:

就是我下面之前所讲的这个:
然后是梯度的表示和梯度下降:

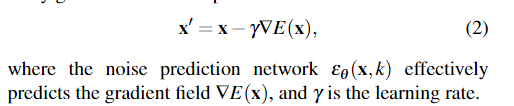
即下图展示的过程:

文章使用了DDPM去逼近条件概率分布而不是联合分布,这也是由之前的论文总结而来。
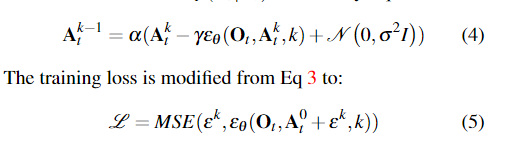

【下面正式开始对论文相关进行分析和理解】
本质上policy从演示中学习,最简单的形式可以表述为学习将观察结果映射到行动的监督回归任务。然而,在实践中,预测机器人动作的独特性质——例如多模态分布的存在、序列相关性和高精度的要求——使这项任务与其他监督学习问题相比显得独特而具有挑战性。
第一个图类似于模仿学习,一个输入对应一个输出
第二个图对应一个能量场(没看懂-——-)
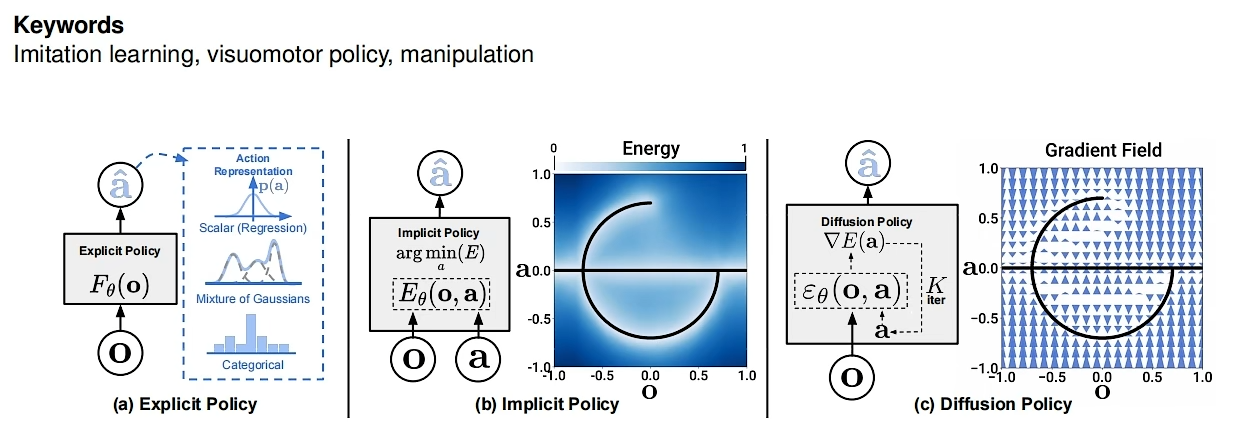
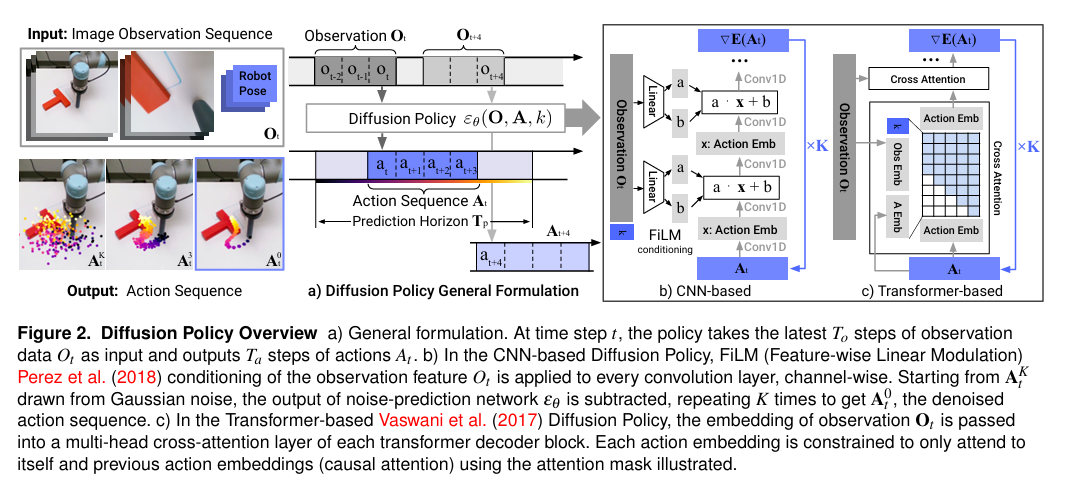
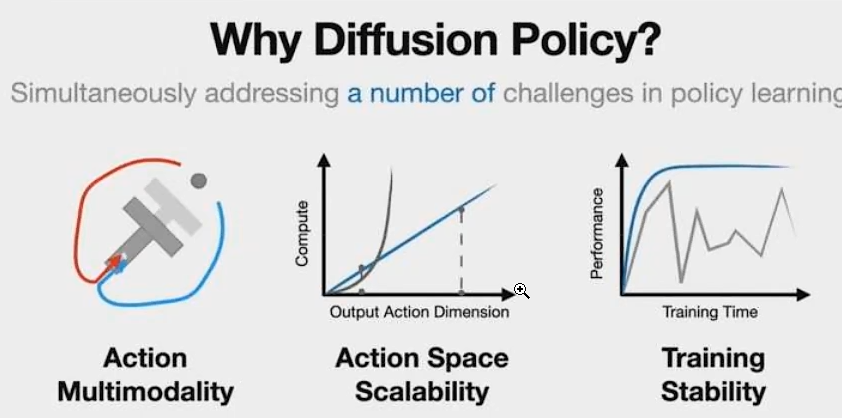
为什么要用Diffusion Policy
a. 解决Multi-Modal(多模态)的问题。
什么是多模态问题?
E.G.假设现在有100只兔子,前面有一个木桩,可能有30只兔子选择左转绕过桩子,有60只选择右转绕过桩子,有10只兔子选择撞死在桩子上。当这些所有的解决方案都合并为一个的时候,问题就变成了一个多模态分布。
传统前馈神经网络本质是一种有很多系数(w)的函数,例如使用MSE(均方误差)进行训练,即以一个目的进行优化为前提,对于给定的输入,只有一种可能的输出。然而,在某些情况下,一个输入可能对应两种不同的输出。
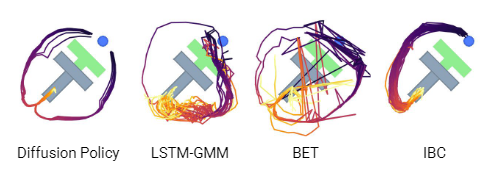
引入了概率分布,使得神经网络不再是一个输入一个输出的函数,而是一个输入可以有多个输出的函数。这种方法提供了更大的灵活性,可以表示各种概率分布,解决了原有方法的限制。
但和实际中机器人系统需要对机器人动作严格控制的思路是相违背的,对于全驱和欠驱系统,无论如何我们都希望可以严格控制机器人执行任务的表现,这也是为什么大多数人没有把机器人动作生成表现为一个概率分布的原因。
但实际过程中,举个例子,如果机器人卡Bug一直撞向桩子,我们如果给他添加概率,有一定概率撞,也有一定概率不撞,这样就可以提高系统的鲁棒性,解决由于严格执行而卡bug卡死的情况。、
”解决某一个特定任务的方法是多样的“
b. Action Space Scalability
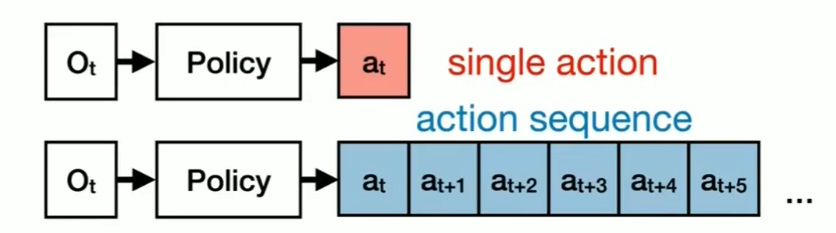
下象棋,想7步,下一步
c. 训练稳定
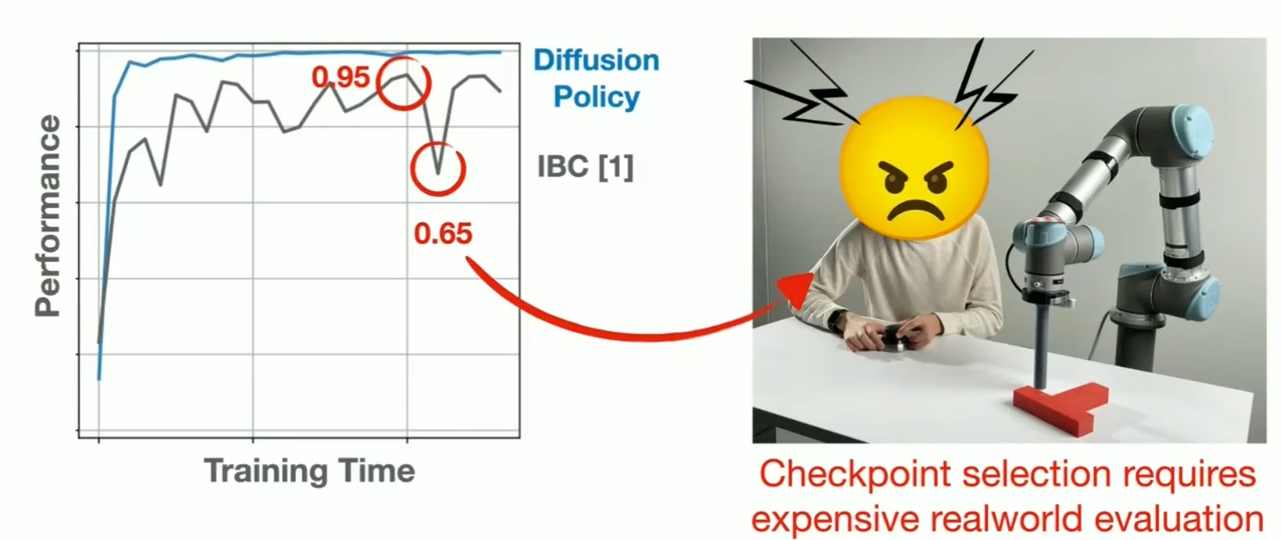
Checkpoints,可能overfit/overtrain/diverge
训练期间可能不知道,就必须在机器人上运行并检查每一个Checkpoints,找到哪一个表现良好。这个过程比较tedious并且是very error-prone process
self-surprising 启发式(自我惊讶)
SUMMARY
5. 3D Diffusion Policy
Obeservation使用深度相机,有深度信息。。
6. Octo
基于大模型大数据
7. DDPM+PPO
未完待续。。。
标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
