首页 > 极客资料 博客日记
FALCON:打破界限,粗粒度标签的无监督细粒度类别推断,已开源| ICML'24
2024-09-10 13:00:03极客资料围观24次
在许多实际应用中,相对于反映类别之间微妙差异的细粒度标签,我们更容易获取粗粒度标签。然而,现有方法无法利用粗标签以无监督的方式推断细粒度标签。为了填补这个空白,论文提出了
FALCON,一种从粗粒度标记数据中无需细粒度级别的监督就能发现细粒度类别的方法。FALCON同时推断未知的细粒度类别和粗粒度类别之间的潜在关系。此外,FALCON是一种模块化方法,可以有效地从多个具有不同策略的数据集中学习。我们在八个图像分类任务和一个单细胞分类任务上评估了FALCON。FALCON在tieredImageNet数据集上超过最佳基线22%,实现了600多个细粒度类别。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Fine-grained Classes and How to Find Them

Introduction
机器学习在具有大量精确标记数据的领域表现出色。虽然粗粒度标签通常是丰富且易于获得的,但由于类别之间微妙的差异和少量具有区分性的特征,精细标签的精确注释却具有挑战性。因此,在许多领域,获取这种精细标签需要领域专业知识和繁琐的人工努力。例如,B细胞和T细胞可以很容易区分,但区分CD4+T细胞和CD8+T细胞等非常细粒度的细胞亚型则需要识别极少量的特定标记。为了自动化获得精细标签的繁琐工作,需要能够区分细粒度标签中微妙差异的机器学习方法。
先前的研究表明,粗粒度标签可用于更有效地学习细粒度类别。弱监督分类方法使用粗粒度标签作为一种弱监督形式,以提高细粒度分类性能。最近,出现了少样本学习方法。它们在一组粗粒度类别上进行训练,然后通过每个类别仅有的几个标记样本进行细粒度分类的适配。然而,所有这些方法都需要预设一组细粒度类别以及获取它们的一小部分样本。
在这项工作中,论文提出了一种名为FALCON(Fine grAined Labels from COarse supervisioN)的方法,它可以在一个粗标记的数据集中发现细粒度类别,并且无需任何监督。FALCON的关键发现是,细粒度预测可以通过结合粗粒度和细粒度类别之间的关系来恢复粗粒度预测。基于这个发现,FALCON开发了一个专门的优化过程,交替进行推断粗粒度和细粒度类别之间的未知关系和训练细粒度分类器。粗粒度和细粒度类别之间的关系是通过解决一个离散优化问题来推断的,而细粒度分类器则使用粗粒度监督和细粒度的伪标签进行训练。此外,FALCON可以无缝地适应和利用具有多个数据集的不兼容粗粒度类别,并以相同的细粒度级别重新标记。
将FALCON与其他备选基准方法在八个图像分类数据集以及生物领域的单细胞数据集上进行了比较。实验结果显示,FALCON在没有监督的情况下有效地发现了细粒度类别,并且在图像和单细胞数据上始终优于基线方法。例如,在包含608个细粒度类别的tieredImageNet数据集上,FALCON的性能比基准方法提高了22%。此外,当使用具有不同粗粒度类别的多个数据集进行训练时,FALCON能够有效地重用不同的注释策略来改进其性能。
Fine-grained Class Discovery
Problem setup
设 \(\mathcal{X}\) 为样本空间, \(\mathcal{Y}_C\) 为包含 \(K_C\) 个粗粒度类别的集合。假设给定了一个粗粒度标记的数据集 \(\mathcal{D}=\{(\mathbf{x}^i,y_c^i)\}_{i=1}^N\) ,其中 \(\mathbf{x}^i\in\mathcal{X}\) , \(y_c^i\in\mathcal{Y}_C\) 。另外,每个样本 \(\mathbf{x}\in\mathcal{D}\) 都与一个细粒度类别 \(y_\text{f}\) 相关联,而这些细粒度类别来自于一个未知的细粒度类别集合 \(\mathcal{Y}_F\) 。假设每个细粒度类别 \(y_\text{f}\in\mathcal{Y}_F\) 都与单个粗粒度类别 \(y_c\in\mathcal{Y}_C\) 相关联,即具有唯一的粗粒度父类。细粒度类别的数量 \(K_F = |\mathcal{Y}_F|\) 大于 \(K_C\) ,并且这个值可以在先前得知或进行估计。给定一个粗粒度标记的数据集 \(\mathcal{D}\) ,目标是发现一组细粒度类别 \(\mathcal{Y}_F\) 。因此,希望仅通过粗粒度标记数据集的监督来恢复细粒度标签 \(\tau_F: \mathcal{X} \rightarrow \mathcal{Y}_F\) 。
Parameterizing the Fine-grained Class Discovery
在FALCON中的一个关键发现是,对细粒度预测和类别关系的组合会产生粗粒度预测。因此,可以利用类别关系将细粒度预测和粗粒度标签联系起来。
使用一个概率分类器 \(f_\theta: \mathcal{X} \rightarrow \Delta^{K_F-1}\) 对细粒度标签 \(\tau_F\) 进行建模,将输入映射到( \(K_F-1\) )维的 \(\Delta^{K_F-1}\) 概率单纯形(每个点代表有限个互斥事件之间的概率分布,每个事件通常被称为一个类别) 。然后,对分类器的细粒度预测 \(\mathbf{p}_\text{f}\) 取argmax,可以得到样本的细粒度类别 \(\mathcal{Y}_F\) 。
这里, \(\theta \in \mathbb{R}^d\) 是细粒度分类器的参数, \(\mathbf{p}_\text{f}\) 是 \(\Delta^{K_F-1}\) 上的一个点。
利用细粒度预测 \(\mathbf{p}_\text{f}\) 和类别关系 \(\mathbf{M}\) 得到粗粒度预测 \(\mathbf{p}_\text{c}\) 。
其中, \(\mathbf{p}_\text{c}\) 是( \(K_C-1\) )维概率单纯形 \(\Delta^{K_C-1}\) 上的一个点, \(\mathbf{M} \in \{0,1\}^{K_F \times K_C}\) 是一个描述细粒度和粗粒度类别关系的二进制矩阵。具体而言,元素 \(\mathbf{M}_{ij}\) 等于1表示第 \(i\) 个细粒度类别与第 \(j\) 个粗粒度类别相关联,否则为0。由于每个细粒度类别只与一个粗粒度类别相关联,矩阵 \(\mathbf{M}\) 的每一行之和为1。因此, \(\mathbf{M}\) 是一个无向二分图的邻接矩阵,用于建模粗粒度和细粒度类别之间的关系。
FALCON通过粗粒度监督同时学习细粒度分类器和类别关系,使用交叉熵目标函数(CE)来利用粗粒度监督,并学习参数 \(\theta\) 和关系 \(\mathbf{M}\) :
通过对离散类别关系 \(\mathbf{M}\) 和连续分类器参数 \(\theta\) 进行联合优化,会导致不稳定且计算成本高昂。为了避免这些问题,论文扩展目标函数并对参数 \(\theta\) 和类别关系 \(\mathbf{M}\) 进行交替优化。
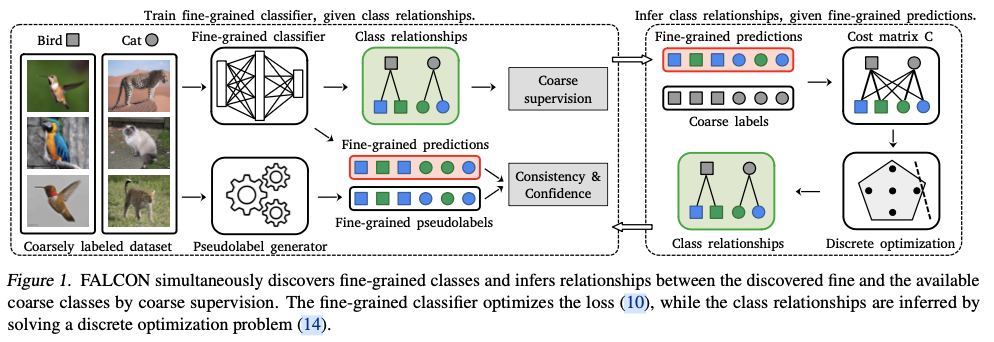
FALCON中的交替优化过程如图1所示,并按以下步骤进行:
- 在给定类别关系 \(\mathbf{M}\) 的情况下,对由参数 \(\theta\) 参数化的细粒度分类器进行训练。
- 根据分类器的细粒度预测和粗粒度标签,推断类别关系 \(\mathbf{M}\) 。
- 该过程重复进行预定义的轮数。
Training Fine-grained Classifier
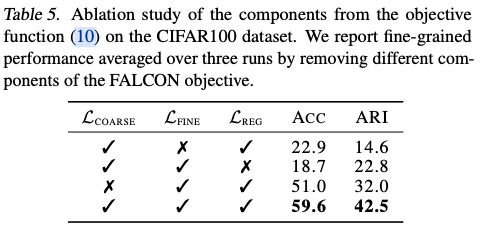
在固定类别关系 \(\mathbf{M}\) 的情况下, \(\mathcal{L}_\text{coarse}(\theta, \mathbf{M}|\mathcal{D})\) 变为 \(\mathcal{L}_\text{coarse}(\theta|\mathbf{M}, \mathcal{D})\) 。但仅通过粗粒度标签训练细粒度分类器,无法在一个粗粒度类别中分开细粒度类别。为了克服这个问题,在FALCON中引入了额外的目标,鼓励细粒度预测的局部一致性和置信度,从而更好地从粗粒度类别中的分离细粒度类别。
-
Consistent and confident fine-grained predictions
给定输入的最近邻,通过强化最大化输入样本预测与相邻样本预测之间的点积来鼓励细粒度预测一致预测。相应的损失 \(\mathcal{L}_\text{NN}\) 是点积的对数几何平均:
其中, \(\mathcal{N}(\mathbf{x}, y_c)\) 表示给定样本 \(\mathbf{x}\) 在同一粗粒度类别 \(y_c\) 内的最近邻样本集合, \(\hat{\mathbf{x}}\) 是 \(\mathcal{N}(\mathbf{x}, y_c)\) 中的一个元素,并且 \(L = |\mathcal{N}(\mathbf{x}, y_c)|\) 。参数 \(\theta_\text{EMA}\) 是在迭代过程中计算参数 \(\theta\) 的指数移动平均值:
其中, \(\gamma\) 是超参数, \(t\) 代表训练迭代次数。与先前研究不同的是,论文从相同粗粒度类别中检索最近邻样本,并使用EMA参数。
损失函数 \(\mathcal{L}_\text{NN}\) 确保了相邻样本之间的细粒度预测的一致性。然而,一致的预测也可能是模棱两可的,这会阻碍形成充分的细粒度类别。因此,通过最小化细粒度预测和目标分布 \(q\) 之间的交叉熵,可以鼓励更有信心地将样本分配到细粒度类别中:
细粒度目标分布 $ q $ 利用粗粒度标签 $ y_c $ 的信息来优化各个细粒度类别的分布。使用类别关系 $ \mathbf {M} $ 和参数 $ \theta_\text{EMA} $ 来定义目标分布 $ q $ ,如下所示:
其中, \(T\) 是一个标量温度超参数, \(\mathbf{s}\) 表示细粒度分类器的逻辑回归。标量 \(Z\) 是一个归一化常数,定义为 \(Z=\sum_{i=1}^{K_F} \mathbf{M}_{i, y_c} \exp( \mathbf{s}^i / T )\) 。
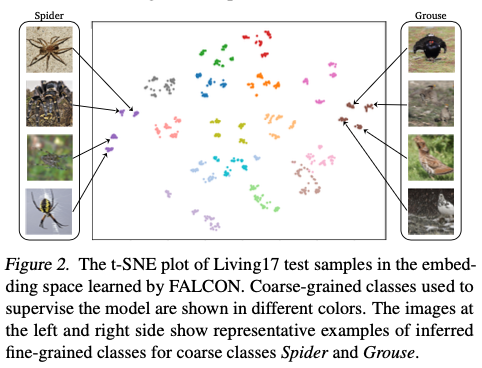
引入的目标分布 \(q\) 和最近邻的细粒度预测可以被视为一种伪标签形式,如图1(左)所示。将损失函数 \(\mathcal{L}_\text{NN}\) 和损失函数 \(\mathcal{L}_\text{conf}\) 合并为一个在细粒度预测的联合损失 \(\mathcal{L}_\text{fine}\) 。
-
Regularization
为了避免退化解,进一步通过引入最大熵损失函数 \(\mathcal{L}_\text{reg}\) 来稳定训练,该损失函数在聚类相关任务中常被使用。
损失函数 \(\mathcal{L}_\text{reg}\) 有助于避免将所有样本分配到相同的细粒度类别的退化解。
-
Total loss of the fine-grained classifier
将这一切综合起来,FALCON优化以下目标来训练细粒度分类器:
其中, \(\lambda_1, \lambda_2\) 和 \(\lambda_3\) 是调制超参数。使用细粒度分类器的预测结果之后,FALCON学习细粒度和粗粒度类别之间的关系。
Inferring Class Relationships
给定细粒度分类器 \(f_\theta\) ,优化时要求对所有可能的类别关系进行离散优化,以找到最优的 \(\mathbf{M}\) 。主要的困难在于,目标函数既是关于 \(\mathbf{M}\) 的非线性函数,又由于庞大的数据集大小 \(N\) ( \(K_C < K_F \ll N\) )而难以进行评估。然而,离散优化求解器需要对目标函数进行多次评估,且仅适用于特定的问题类别,如线性目标函数。为了克服上述问题,FALCON采用了对目标函数近似,从而实现了对类别关系的高效推断。
-
Approximated coarse-grained supervision
首先固定细粒度分类器的参数 \(\theta\) ,并将粗粒度标签的损失 \(\mathcal{L}_\text{coarse}\) 以矩阵形式重新表达:
其中, \(\mathbf{Y}_{oh} \in \{0, 1\}^{N\times K_C}\) 是一个将粗粒度标签表示为one-hot向量的矩阵,而 \(\mathbf{P} \in [0, 1]^{N\times K_F}\) 是将细粒度预测聚集到行中的矩阵。对数操作是逐元素进行的,而 \(\text{tr}(\cdot)\) 是迹运算符(矩阵对角线之和)。
为了克服讨论中的挑战,使用泰勒展开对损失 \(\mathcal{L}_\text{coarse}\) 进行近似,并以计算效率高的方式对其进行重新表述:
成本矩阵 \(\mathbf{C} = \mathbf{Y}_{oh}^T \mathbf{P} \in \mathbb{R}^{K_C \times K_F}_+\) 有效地编码了粗细类之间的连接强度,每个成本矩阵元素 \(\mathbf{C}_{ij}\) 与粗类 \(j\) 被分配到细类 \(i\) 的样本数量成比例。因此,上述公式的最优解仅保留了粗细类之间最强的连接。需要注意的是,新目标可以比原目标更高效地进行评估,因为矩阵 \(\mathbf{Y}_{oh}^T\mathbf{P}\) 可以预先计算。
-
Regularization
计算目标 \(\mathcal{L}_\text{coarse}^\text{lin}\) 的最优解可能会导致在粗粒度类之间出现严重不平衡的细粒度类分配。因此,引入了一个额外的正则化项,惩罚细粒度类在粗粒度类之间的分配偏差:
其中, \(\boldsymbol{1}_{K_F}\) 表示 \(K_F\) 维全为1的列向量。因此, \(\mathbf{M}^T\boldsymbol{1}_{K_F}\) 是一个 \(K_C\) 维的向量,其值对应于每个粗粒度类关联的细粒度类的数量。常数 \(K_F^2/K_C^2\) 修正了损失,使其在平衡分配的情况下为零。
-
Total loss for inferring class relationships
FALCON通过求解以下优化问题来恢复细粒度类和粗粒度类之间的关系 \(\mathbf{M}\) :
其中, \(\lambda_M\) 是一个超参数,用于控制 \(\mathcal{L}_\text{bal}\) 的影响力。集合 \(\mathcal{M}\) 包含所有可能的类别关系:
优化公式本质上是一个带有线性约束的整数二次规划问题,该问题涉及仅有 \(K_F\cdot K_C\) 个二进制变量的优化。因此,即使由此产生的问题本质上是NP-hard的,也可以迅速地利用现代硬件计算出解。实验证明,FALCON可以应用于包含数百个细粒度类别的真实数据集中。
Training on Multiple Datasets
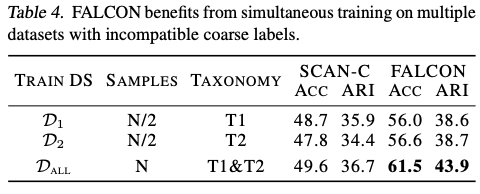
细粒度类别可以以不同的方式被分组成粗粒度类别。例如,可以根据饮食习性(食肉动物与杂食动物)、体型大小(小型与大型)或生物分类学(Canis lupus与Canis familiaris)对动物进行分组。因此,尽管对相同细粒度类别的实例进行了聚合,但数据集往往具有不同的标签。FALCON可以无缝地应用于在具有不同粗粒度标签的多个数据集上的训练。
具体来说,设 \(\mathcal{D}_l = \{(\mathbf{x}^i, y_c^i)\}_{i=1}^{N_l}\) 是一个数据集,其中 \(\mathbf{x}^i \in \mathcal{X}\) , \(y_c^i \in \mathcal{Y}_C^l\) ,而 \(\mathcal{Y}_C^l\) 是数据集特定的粗粒度类别集合。假设每个数据集 \(\mathcal{D}_l\) 的样本都可以与共享的细粒度类别集合 \(\mathcal{Y}_F\) 中的细粒度类别关联,将来自 \(D\) 个数据集的样本合并为一个组合数据集 \(\mathcal{D}_\text{all}\) :
\(\mathcal{D}_\text{all}\) 中的每个数据点都是一个由输入、粗粒度标签和样本来源数据集的索引组成的三元组,通过建模 \(D\) 个数据集特定的映射 \(\mathbf{M}_l\) 来扩展:
因此,将多个数据集集成到FALCON框架中只需要推断出 \(D\) 个数据集特定的类别关系 \(M_l\) 。与单个数据集的情况类似,FALCON通过解决公式14推断出数据集特定的类别关系。所有 \(D\) 个离散优化问题是相互独立的,可以并行求解。
Experimental Setup
Datasets & Metrics
-
Datasets
在八个图像分类数据集上评估了FALCON,包括Living17、Nonliving26、Entity30、Entity13、tieredImageNet、CIFAR100、CIFAR-SI和CIFAR68数据集。数据集Living17、Nonliving26、Entity30和Entity13来自于BREEDS基准测试。
- 对于
tieredImageNet数据集,将训练、验证和测试的分类体系合并为一个包含 \(608\) 个细粒度类别和 \(34\) 个粗粒度类别的单一数据集。 - 对于
CIFAR100数据集,使用具有 \(20\) 个粗粒度类别和 \(100\) 个细粒度类别的原始标签。原始的CIFAR100数据集中,每个粗粒度类别都有相同数量的细粒度类别,每个细粒度类别中也有相同数量的样本。因此,额外引入了两个不平衡版本的CIFAR100数据集,命名为CIFAR68和CIFAR-SI数据集。 - 在
CIFAR68数据集的情况下,从原始数据集中删除了 \(32\) 个细粒度类别,以使粗粒度类别中的细粒度类别数量不平衡。 - 在
CIFAR-SI数据集的情况下,从每个细粒度类别中删除了高达 \(70\%\) 的样本,实际上导致了样本分布的不平衡。
此外,为了表明FALCON具有广泛的适用性,考虑了来自生物领域的单细胞RNA测序数据集。在从COVID-19患者血液样本中收集的PBMC数据集上评估了FALCON。任务是在给定粗粒度细胞类型的情况下将细胞分类为细粒度细胞亚型。根据对应于细粒度标签的真实细胞亚型对该方法进行评估。PBMC数据集极度不平衡(基尼系数大于0.5)。在单细胞数据上进行了转导性设置下的性能评估。
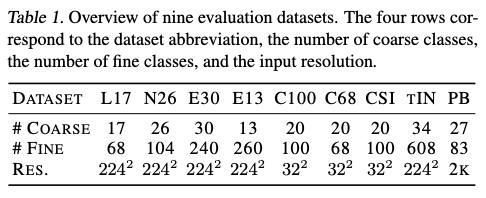
所有考虑的数据集的概述如表1所示。缩写L17代表Living17,N26代表Nonliving26,E30代表Entity30,E13代表Entity13,C100代表CIFAR100,C68代表CIFAR68,CSI代表CIFAR样本不平衡,tIN代表tieredImageNet,PB代表PBMC。
-
Metrics
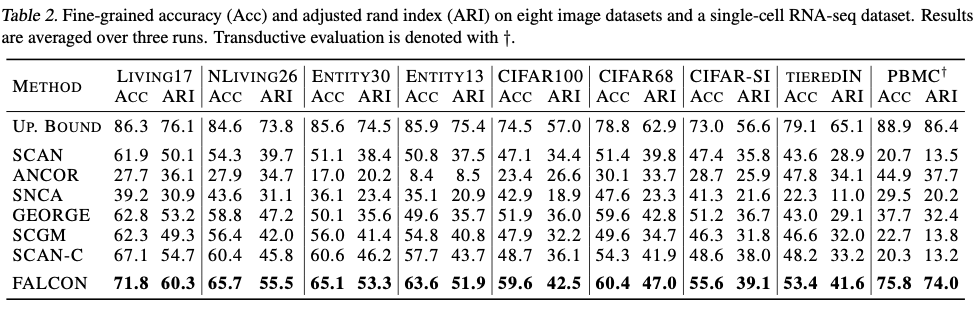
在没有细粒度基准标签的情况下训练了FALCON和基线模型。因此,报告细粒度聚类准确度作为评估指标。
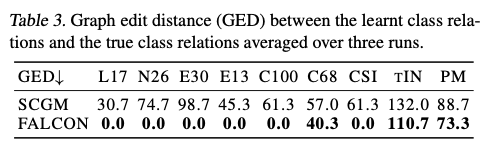
在这里, \(\mathcal{P}(\mathcal{Y}_\text{f})\) 是所有细粒度类别标签的排列组合。在实践中,可以使用匈牙利算法高效地计算该度量。此外,我们还报告了调整兰德指数(ARI)。由于FALCON还学习了类别关系,我们使用图编辑距离(GED)报告了学习到的标签关系与地面真相图之间的差异。图编辑距离计算必须添加或移除的节点和边的数量,以使其匹配目标图。
Baselines
由于没有专门为粗粒度监督下细粒度类别发现的方法,将FALCON与可以应用于该设置的方法进行比较,包括改编为细粒度类别发现的聚类和跨粒度少样本方法。
SCAN是一种深度聚类方法,直接将其应用于细粒度类别发现,通过对数据进行聚类。然而,SCAN在训练过程中无法利用有关粗粒度类别的信息。因此,额外通过在同一粗粒度类别中强制保持邻居之间的一致预测来对SCAN进行了改进。这种改进使得SCAN能够利用粗粒度监督。我们将这个基准方法称为SCAN-C。
论文进一步将跨粒度少样本学习方法作为基线进行比较。ANCOR是一种跨粒度少样本学习方法,它学习细粒度表示空间。因此,对提取的特征运行K均值聚类以恢复细粒度预测,使用相同的方法来改编SNCA。SCGM是一种少样本学习方法,可直接应用于细粒度类别发现,因为它提供了细粒度预测。
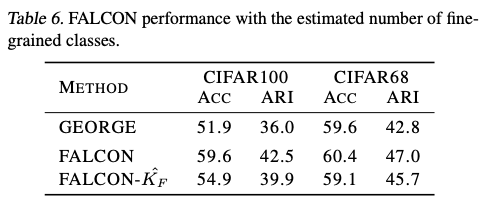
论文还加入GEORGE,它通过分布鲁棒优化粗分类目标。GEORGE只学习细粒度表示空间,因此我们再次运行K均值算法来恢复细粒度预测。
最后,可以通过对细粒度标签进行经验风险最小化(ERM)来确定性能的上限。
Implementation Details
对于来自CIFAR数据集的小尺寸图像,使用ResNet18作为骨干网络,并对剩余的五个图像数据集使用ResNet50作为骨干网络。使用自监督预训练方法MoCoV3对所有方法(即FALCON和所有基线方法)进行初始化。在训练过程中,更新模型的所有参数。将输入的弱增强与 \(\theta_\text{EMA}\) 配对,将强增强与 \(\theta\) 配对。使用自监督特征表示之间的距离来检索最近邻。在Optuna中使用TPE算法对CIFAR100数据集进行超参数搜索。使用Gurobi解决离散优化问题。
在单细胞数据的情况下,使用具有4个线性层和ReLU激活的随机初始化MLP。通过计算前2k个高度变异基因的距离来检索最近邻。
Experimental Evaluation


如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
