首页 > 极客资料 博客日记
c#学习笔记(一)
2024-09-01 22:30:03极客资料围观25次
基础语法
文档注释&代码块
/// <summary>
/// 待机
/// </summary>
#region 物体移动
sq.transform.Translate(new Vector3(5,0,0));
#endregion
字符串格式化输出
使用 $ 可进行格式化输出
C# string 字符串的前面可以加 @(称作"逐字字符串")将转义字符(\)当作普通字符对待
int age = 10;
string str1 = $"my age is {age}";
string str = @"C:\Windows";
类型转换
C# 中的类型转换可以分为两种:隐式类型转换和显式类型转换(也称为强制类型转换)。
隐式类型转换
隐式转换是不需要编写代码来指定的转换,编译器会自动进行。
隐式转换是指将一个较小范围的数据类型转换为较大范围的数据类型时,编译器会自动完成类型转换,这些转换是 C# 默认的以安全方式进行的转换, 不会导致数据丢失。
例如,从 int 到 long,从 float 到 double 等。
从小的整数类型转换为大的整数类型,从派生类转换为基类。将一个 byte 类型的变量赋值给 int 类型的变量,编译器会自动将 byte 类型转换为 int 类型,不需要显示转换。
byte b = 10;
int i = b; // 隐式转换,不需要显式转换
int intValue = 42;
long longValue = intValue; // 隐式转换,从 int 到 long
显式转换
显式类型转换,即强制类型转换,需要程序员在代码中明确指定。
显式转换是指将一个较大范围的数据类型转换为较小范围的数据类型时,或者将一个对象类型转换为另一个对象类型时,需要使用强制类型转换符号进行显示转换,强制转换会造成数据丢失。
例如,将一个 int 类型的变量赋值给 byte 类型的变量,需要显示转换。
int i = 10;
byte b = (byte)i; // 显式转换,需要使用强制类型转换符号
double doubleValue = 3.14;
int intValue = (int)doubleValue; // 强制从 double 到 int,数据可能损失小数部分
int intValue = 123;
string stringValue = intValue.ToString(); // 将 int 转换为字符串
C# 类型转换方法
当然,c#也内置了许多类型转换方法
| 序号 | 方法 & 描述 |
|---|---|
| 1 | ToBoolean 如果可能的话,把类型转换为布尔型。 |
| 2 | ToByte 把类型转换为字节类型。 |
| 3 | ToChar 如果可能的话,把类型转换为单个 Unicode 字符类型。 |
| 4 | ToDateTime 把类型(整数或字符串类型)转换为 日期-时间 结构。 |
| 5 | ToDecimal 把浮点型或整数类型转换为十进制类型。 |
| 6 | ToDouble 把类型转换为双精度浮点型。 |
| 7 | ToInt16 把类型转换为 16 位整数类型。 |
| 8 | ToInt32 把类型转换为 32 位整数类型。 |
| 9 | ToInt64 把类型转换为 64 位整数类型。 |
| 10 | ToSbyte 把类型转换为有符号字节类型。 |
| 11 | ToSingle 把类型转换为小浮点数类型。 |
| 12 | ToString 把类型转换为字符串类型。 |
| 13 | ToType 把类型转换为指定类型。 |
| 14 | ToUInt16 把类型转换为 16 位无符号整数类型。 |
| 15 | ToUInt32 把类型转换为 32 位无符号整数类型。 |
| 16 | ToUInt64 把类型转换为 64 位无符号整数类型。 |
这些方法都定义在 System.Convert 类中,使用时需要包含 System 命名空间。它们提供了一种安全的方式来执行类型转换,因为它们可以处理 null值,并且会抛出异常,如果转换不可能进行。
例如,使用 Convert.ToInt32 方法将字符串转换为整数:
string str = "123";
int number = Convert.ToInt32(str); // 转换成功,number为123
类型转换方法
C# 提供了多种类型转换方法,例如使用 Convert 类、Parse 方法和 TryParse 方法,这些方法可以帮助处理不同的数据类型之间的转换。
使用 Convert 类
Convert 类提供了一组静态方法,可以在各种基本数据类型之间进行转换。
实例
string str = "123";
int num = Convert.ToInt32(str);
使用 Parse 方法
Parse 方法用于将字符串转换为对应的数值类型,如果转换失败会抛出异常。
实例
string str = "123.45";
double d = double.Parse(str);
使用 TryParse 方法
TryParse 方法类似于 Parse,但它不会抛出异常,而是返回一个布尔值指示转换是否成功。
实例
string str = "123.45";
double d;
bool success = **double**.TryParse(str, **out** d);
if (success) {
Console.WriteLine("转换成功: " + d);
} else {
Console.WriteLine("转换失败");
}
C#中的引用参数传递
在C++中,我们需要传递实参时只需要使用&修饰形参即可实现引用参数传递。但在C#中,我们需要使用关键字ref来进行该操作
void test01()
{
int a = 10;
Add(ref a,10);
Debug.Log(a);//20
}
int Add(ref int a, int b)
{
return a+=b;//20
}
不同于ref关键字,我们也能用类似的out关键字来进行引用参数传递
out关键字:
out也用于引用传递,允许方法修改传递给它的变量的值。- 不同于
ref,调用方法时传递给out参数的变量不需要被初始化。 out参数通常用于方法需要返回一个以上的值,并且希望明确表示参数是输出参数。
使用场景:
- 当你想要确保方法的调用者提供了一个有效的值,并且方法会修改这个值,使用
ref。 - 当你想要方法的调用者提供一个变量,但不需要事先初始化,并且方法会提供这个变量的值,使用
out。
语法示例:
csharpvoid MethodWithRef(ref int number) {
number += 10; // number的原始值被修改
}
void MethodWithOut(out int number) {
number = 10; // number被赋予一个值
}
调用示例:
int value = 5;
MethodWithRef(ref value); // value现在是15
int anotherValue;
MethodWithOut(out anotherValue); // anotherValue现在是10
封装
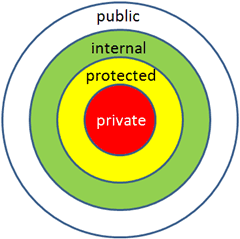
相比于C++,C#中的访问修饰符要多出两个类型,一个是internal,另一个是与protected结合的protected internal
- public:所有对象都可以访问;
- private:对象本身在对象内部可以访问;
- protected:只有该类对象及其子类对象可以访问
- internal:同一个程序集的对象可以访问;(可以被定义在该成员所定义的应用程序内的任何类或方法访问)
- protected internal:访问限于当前程序集或派生自包含类的类型。(允许在本类,派生类或者包含该类的程序集中访问。)
继承
c#的继承语法大体和c++类似,都是 访问修饰符 class 子类: 父类
但是继承后的子类如何去写构造函数,则依靠于base
base:当前类的基类(父类)
public class Animal
{
public int age;
public string name;
public Animal(string name, int age)
{
this.name = name;
this.age = age;
}
}
public class Dog: Animal
{
public Dog(string name, int age):base(name, age)
{}
public void Bark()
{
}
}
多态
虚函数和重写
与c++不同,c#中的重写(覆盖基类中的函数)需要加上关键字override
public class Animal
{
/*
虚函数
1.提供默认逻辑,因为一些子类不需要重写
2.提供可选的逻辑(用基类base调用)
*/
public virtual void Bark()
{
Debug.Log("张嘴开叫");
}
}
public class Dog: Animal
{
public override void Bark()
{
Debug.Log("张嘴狗叫");
}
}
抽象类和抽象函数
c#中,抽象要加上关键字abstract,抽象函数也约等于c++中的纯虚函数
// 抽象类
public abstract class Animal
{
// 抽象方法,子类必须实现
public abstract void MakeSound();
// 非抽象方法,可以有实现
public void Eat()
{
Console.WriteLine("The animal is eating.");
}
}
// 继承抽象类的子类,必须实现抽象方法
public class Dog : Animal
{
public override void MakeSound()
{
Console.WriteLine("Woof!");
}
}
// 使用
public class Program
{
public static void Main()
{
Animal myDog = new Dog(); // 可以创建抽象类的实例,但需要是其子类
myDog.MakeSound(); // 输出: Woof!
myDog.Eat(); // 输出: The animal is eating.
}
}
里氏转换
概念:
里氏转换主要是:子类和父类的类型转换
- 子类转父类——隐式转换
- 父类转子类——显示转换(用的少,有风险,要确保类型兼容)
public class Animal
{
public virtual void MakeSound()
{
Console.WriteLine("Some sound");
}
}
public class Dog: Animal
{
public override void MakeSound()
{
Console.WriteLine("Bark!");
}
}
public class Program
{
public static void Main()
{
Dog dog = new Dog;
Animal ani = new Animal;
doSound(dog);//子类转父类——隐式转换
doBark(ani);//父类转子类——显示转换
}
public void doSound(Animal animal)
{
Console.WriteLine("Some sound");
}
public void doBark(Animal animal)//此处约定传递过来的参数要么是Animal,要么是Animal的子类通过隐式转换传递过来的
{
//强制转换,会报错
Dog dog = (Dog)animal;
//as转换,不会报错
Dog dog2 = animal as Dog;
//Cat cat = (Cat)animal; 类型不兼容,会报错
}
}
万物基类object
如果一个类不设置基类的话,那么他的基类就是object,同时object下有几个虚函数可以重载,这里先重点讲一下ToString()。
因为万物基类都是object,所以任何类型的对象都可以隐式转换为object
接口
c#中的继承是单继承,即一个类只能继承一个基类;但是无论是否有继承某个类,都可以进行多个接口的继承
接口关键字:interface
public interface ITalk
{
void Talk();//实际上是抽象函数,默认为public,不需要定义访问修饰符
}
public interface IMove
{
void IMove();
}
namespace animal
{
public abstract class Animal
{
public string name;
public override string ToString()
{
return $"I'm {name}";
}
}
public class Parrot: Animal, ITalk, IMove //多个接口的继承
{
public void Talk() //接口不需要加关键字override
{
Console.WriteLine("Some sound");
}
}
}
public class Human: ITalk, IMove //无论是否有基类
{
public void Talk()
{
Console.WriteLine("Some sound");
}
}
public class Robot: ITalk, IMove
{
public void Talk()
{
Console.WriteLine("Some sound");
}
}
public class Program
{
public static void Main()
{
Robot robot = new Robot();
Person person = new Person();
Parrot parrot = new Parrot();
Talk(robot);//隐式转换
Talk(person);//隐式转换
Talk(parrot);//隐式转换
ITalk talker = robot;//隐式转换
Robot robot1 = (Robot)talker//强制转换
}
//公共函数
public void Talk(ITalk talker)
{
talker.Talk();
}
属性
类似成员数据与成员函数相结合
概念
属性由两个访问器组成:get访问器和set访问器。get访问器用于返回属性的值,而set访问器用于设置属性的值。属性可以是只读的(只有get访问器)、只写的(只有set访问器)或读写的(同时有get和set访问器)。
属性的定义
属性的定义通常遵循以下格式:
public class MyClass
{
private int myField; // 私有字段
// 属性
public int MyProperty
{
get
{
return myField;
}
set
{
myField = value;
}
}
}
在这个示例中,MyProperty 是一个属性,它封装了私有字段 myField。get 访问器返回 myField 的值,set 访问器将传入的值(通过 value 关键字)赋给 myField。
属性的使用
属性的使用与公共字段类似,但可以在访问时执行额外的逻辑。
MyClass obj = new MyClass();
obj.MyProperty = 42; // 调用 set 访问器
int value = obj.MyProperty; // 调用 get 访问器
自动实现的属性
C# 还提供了自动实现的属性,这种属性在定义时不需要显式声明私有字段,编译器会自动生成一个隐藏的私有字段。
public class Person
{
public string Age { get; set; }
}
public class Program
{
public static void Main()
{
myPerson.Age = 10;
Console.WriteLine(myPerson.Age); // 输出: 10
}
}
自动实现的属性使得代码更加简洁,但在某些情况下可能需要自定义 get 和 set 访问器的逻辑。
只读和只写属性
只读属性只有 get 访问器,只写属性只有 set 访问器。
public class Circle
{
private double radius;
public Circle(double radius)
{
this.radius = radius;
}
public double Radius
{
get
{
return radius;
}
}
public double Area
{
get
{
return Math.PI * radius * radius;
}
}
}
值类型与引用类型
值类型
int a =3;
int b - a;
在b=a时,会重新开辟内存空间并完整的复制一次a的数据,相当于两者无关,只是在复制的时两者数据相等而已
主要的值类型:枚举、结构体、int、float、bool等
比较(相等/不等)时一般是判断两者的值是否相同
结论:值类型在赋值时都是拷贝值
函数调用的过程也是赋值,因此参数默认为值传递
引用类型
Dog dahuang = new Dog0;
Dog dog = dahuang;
在dog=dahuang时,dog会引用dahuang的内存地址,相当于两者是一个对象,只是名称不一样
主要的引用类型:class、interface
比较(相等/不等)时一般是判断两者是否引用同一对象
函数调用的参数类型是class时默认为引用
结论:引用类型在赋值时都是拷贝引用,和原先的变量是同一个对象
为什么需要这种区别?
值类型都是轻量级数据,用完就放弃(销毁、回收),在C#中一般过了的作用域就回收掉。但是会有传递的需求,因为是轻量级数据,复制成本也不高,所以采用这种方案。
相对的,引用类型一般是重量级数据,那么它的复制成本就高。不适合采用值类型的方案。但是这也不意味着引用类型就不在销毁,当一个对象再也没有人引用时会被标记为“无用”状态等待系统自动的回收,但是这个回收是有成本
class中的值类型:修改对象内的成员都要用对象名.成员名称去做到
特殊的引用类型string
常用成员
Length:字符串长度IndexOf:A字符串在B字符串中第一次出现的地方LastIndexOf:A字符串在B字符串中最后一次出现的地方Replace:替换指定的字符ToUpper:转为大写ToLower:转为小写
字符串的特殊性
首先string是引用类型,底层使用了“常量池”的技术,也就是如果存在某个字符串,则不会实例化一个新的字符串,而是复用之前的引用
string str1 = "ddd";
string str2 = "ddd";
str1 = "CCC"
上面代码中str1和str2是同一个应用,但是str1修改后,str2并不会修改,这就是string的特殊性
数组
基础概念
定义: 数组是一种数据结构,用于存储一系列相同类型的元素。
用途: 用于存储和访问一系列元素。
类型:
- 数组可以是任何基本数据类型(如整数、浮点数、字符等)或引用数据类型(如对象、数组等)
- 数组中可以存放任何类型,但数组本身是引用类型
- 数组中的数据如果没有设置值,那么会是该类型的默认值,引用就是null
数组声明&定义
在C#中,你可以使用以下方式声明数组:
int[] intArray; // 声明一个整数数组
string[] stringArray; // 声明一个字符串数组
int[] intArray2 = new int[10];// 定义一个整数数组
string[] stringArray2 = new string[10];// 定义一个字符串数组
数组初始化
你可以使用以下方式初始化数组:
int[] intArray = {1, 2, 3, 4, 5}; // 初始化一个整数数组
int[] intArray = new int[] {1, 2, 3, 4, 5};
string[] stringArray = {"apple", "banana", "cherry"}; // 初始化一个字符串数组
string[] stringArray = new string[] {"apple", "banana", "cherry"};
数组访问
你可以使用索引来访问数组中的元素。索引从0开始。
int firstElement = intArray[0]; // 访问第一个元素
string secondElement = stringArray[1]; // 访问第二个元素
数组长度
你可以使用Length属性来获取数组的长度。
int arrayLength = intArray.Length; // 获取数组长度(定义长度而非有效长度)
数组排序
你可以使用Array.Sort方法来对数组进行排序。
Array.Sort(intArray); // 对整数数组进行升序排序
数组反转
你可以使用Array.Reverse方法来反转数组。
Array.Reverse(intArray); // 反转整数数组
数组遍历
你可以使用for循环或foreach循环来遍历数组。
for (int i = 0; i < intArray.Length; i++)
{
Console.WriteLine(intArray[i]); // 遍历整数数组
}
foreach (int item in intArray)
{
Console.WriteLine(item); // 遍历整数数组
}
数组排序示例
int[] intArray = {5, 3, 1, 4, 2};
Array.Sort(intArray);
foreach (int item in intArray)
{
Console.WriteLine(item); // 输出排序后的数组
}
数组反转示例
int[] intArray = {5, 3, 1, 4, 2};
Array.Reverse(intArray);
foreach (int item in intArray)
{
Console.WriteLine(item); // 输出反转后的数组
}
交错数组
交错数组是数组的数组(因为数组中可以放任何类型,所以也可以放数组),其中每个子数组可以有不同的长度。例如:
int[][] jaggedArray = new int[3][]; // 声明一个包含3个子数组的交错数组
jaggedArray[0] = new int[1]; // 初始化第一个子数组
int[][] nums = new int[][]
{
new int[] {0,1,2,3,4,5,6},
new int[] {0,1,2,3,4},
new int[] {0,1,2,3},
new int[] {0,1},
};
多维数组
多维数组也是数组的数组,可以通过多个索引来访问元素,子数组的维度确定。例如,二维数组的声明和初始化如下:
int[,] multiDimensionalArray = new int[2, 3]; // 声明一个2x3的二维数组
int[,] nums2 = new int [2,3]
{
{1,2,3},
{4,5,6},
};
交错数组和多维数组的区别
对比维度和存储方式
- 多维数组具有固定的维度大小,即每一行或每一列的元素数量是相同的。多维数组在内存中是连续存储的,可以通过线性索引访问元素。
- 交错数组的每一行可以有不同的长度,即它是由多个一维数组组成的数组。交错数组的元素是引用类型,指向各自的一维数组,因此它们在内存中不是连续存储的。
声明和初始化差异
- 多维数组的声明需要指定所有维度的大小,例如
int[3, 4]声明了一个3行4列的二维数组。 - 交错数组的声明只需要指定第一维的长度,例如
int[][]声明了一个可以包含多个一维数组的交错数组。后续的一维数组可以在声明后进行初始化,例如jaggedArray[0] = new int[5]。
访问方式
- 多维数组通过两个或多个索引来访问元素,例如
array[i, j]。 - 交错数组通过两个索引来访问元素,第一个索引访问一维数组,第二个索引访问该一维数组中的元素,例如
jaggedArray[i][j]。
内存使用和性能考量
- 多维数组由于其连续存储的特点,通常在内存中占用更紧凑,访问速度较快。
- 交错数组由于非连续存储的特点,可能在内存中占用不如多维数组紧凑,但它们提供了更大的灵活性,尤其是在处理不规则数据结构时。
标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
