首页 > 极客资料 博客日记
源码解析之为何要用ConcurrentHashMap
2024-08-21 14:30:04极客资料围观32次
为什么要用ConcurrentHashMap?
ConcurrentHashMap是JUC包下的一个线程安全的HashMap类,我们都知道多线程的场景下要用ConcurrentHashMap来代替HashMap使用,有没有想过为什么不能用HashMap,为什么能用ConcurrentHashMap呢?下面我通过走源码的方式,带大家看一看其中的一些细节!
HashMap
map数组的一种,JDK1.8中的HashMap以数组+链表/红黑树的形式存在,这里不做过多解释
当我们在执行多线程任务时,若是操作的资源为HashMap类型时就可能会导致程序出现并发异常,如图
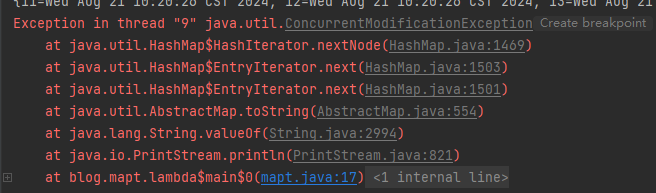
点到nextNode这个方法中去看源码,原因很明显,如图
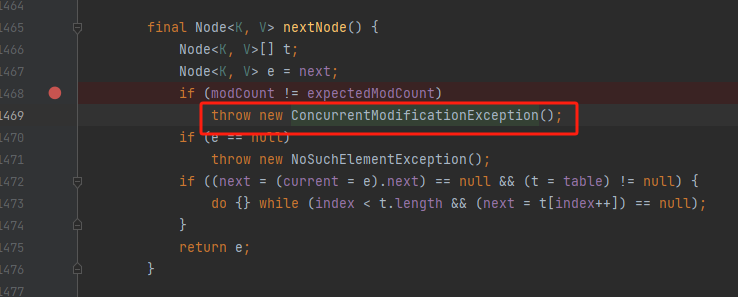
那么,if判断中的两个变量是干什么的呢,为什么这俩变量不相同就要抛出一个异常?
首先,我们看一下我们从创建Hashmap变量到抛出异常这段时间内都做了些什么事情
整个流程的代码如下
public static void main(String[] args) {
HashMap<String,String> map = new HashMap<>();
for (int i = 0;i < 20; i++){
new Thread(()-> {
map.put(Thread.currentThread().getName(),new Date().toString());
System.out.println(map);
},String.valueOf(i)).start();
}
}
我们点进HashMap的方法中的构造方法能看到,这里只给了loadFactor这个变量一个初始值,也就是我们熟知的加载因子0.75

我们再去看一下put方法都干了些什么
put->putVal
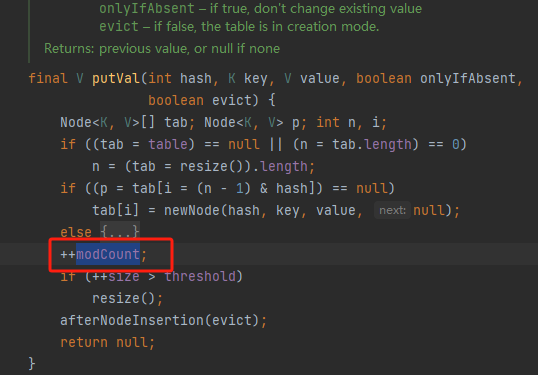
点开后发现,这不就是我们上面看到的if判断中的第一个变量吗?我们点到这个变量的定义的地方可以看到,这是一个int类型的且并未赋值

我们通过这点能得到一个初步的结论,当我们每执行一次put方法的时候,这个值就会进行一次+1的操作
大家可以看到下面还有一个叫afterNodeInsertion的方法,我们点开后发现是一个空方法,再看上边的注释,大概意思是给LinkedHashMap提供的回调的方法,LinkedHashMap是HashMap的一个子类,我们不必理会
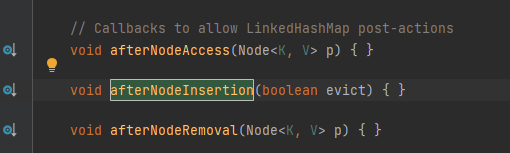
然后我们点开println方法
println->valueOf->toString
找到我们HashMap重写的toString方法,我们发现在HashMap中并没有找到被重写的toString方法,那么我们直接去搜一下他的父类
搜查过程中,如果用Ctrl+f搜索整个类,会看到有一条toString查询记录,此处为HashMap的内部类Node的方法,并非HashMap的

发现AbstractMap类中果然重写了toString方法
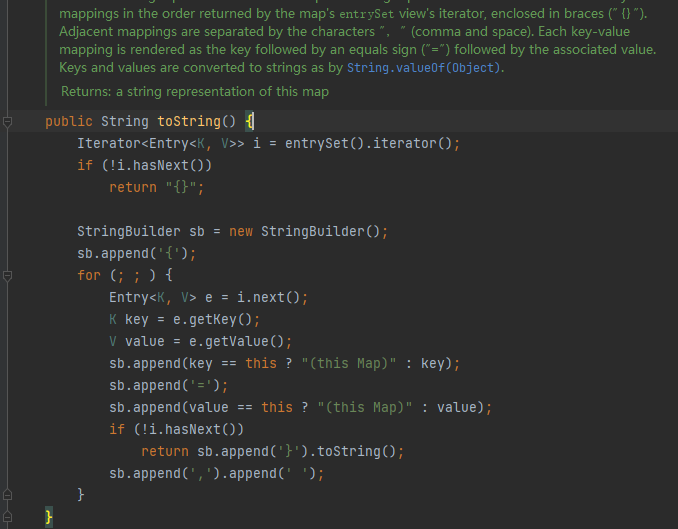
此处我们终于看到了迭代器,我们再返回HashMap类去看一下entrySet方法都干了啥

因为我们走过了put方法,所以此时HashMap中的entrySet是有内容的,可以看到这里是直接把entrySet返回了

entrySet实际上就是一个Set集合,将我们HashMap中的存储单元Entry放到了里面(HashMap.put)
然后我们通过泛型找到实现集合接口中迭代器方法的位置,又是一个HashMap的内部类,EntrySet
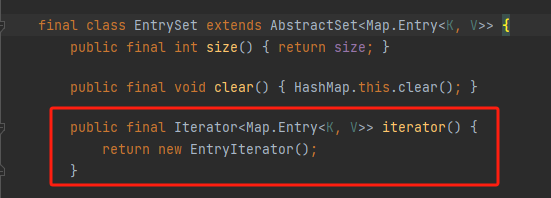
发现又一个没见过的类,我们顺势点开
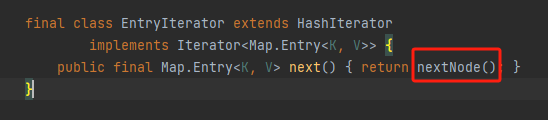
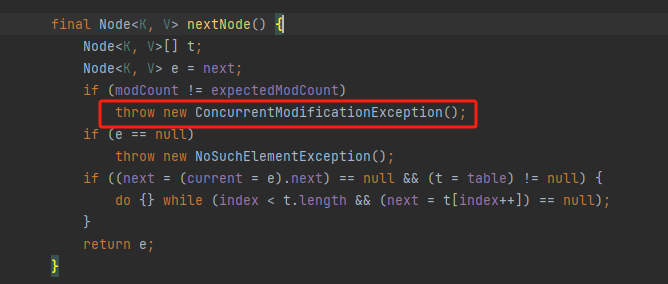
点开nextNode方法后发现,哎,这不是报错的地儿吗,到现在我们modCount也有了,报错的节点也找到了,还差一个expectedModCount没找到呢,于是在一通检查后,突然想到,会不会在某个构造方法中,回去看了一下EntryIterator也没有自己写构造方法呀,于是打开了他的父类,一下子豁然开朗,直接看图吧

到这,这俩哥们总算找齐了,那么这里问题又来了,给expectedModCount赋的就是modCount的值呀,这俩哥们咋还能不一样呢
答案也浮出水面了,单线程下肯定是不会出问题,可是我们是多线程操作呀,如果A线程刚给完值,B线程跑putVal方法去了,跑完modCount+1了,然后A线程紧接着走到了nextNode方法中,一对比就不对了,然后就抛异常了
所以说HashMap在并发场景下还是很容易出问题的
ConcurrentHashMap
HashMap在多线程的场景下不能用了,不安全呀,于是适配多线程的线程安全的HashMap:ConcurrentHashMap应运而生
然后我们把原代码中的HashMap换成ConcurrentHashMap
public static void main(String[] args) {
ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();
for (int i = 0;i < 20; i++){
new Thread(()-> {
map.put(Thread.currentThread().getName(),new Date().toString());
System.out.println(map);
},String.valueOf(i)).start();
}
}
执行了N遍,确实不报错了,每次循环都能打印成功,如此神奇的东西,让我们看看为什么他不报错了
首先点开这个类进去看看

发现这个类也继承了AbstractMap类,说明与HashMap是师出同门的呀,然后我们再去找上边那俩兄弟的时候发现,不见了,然后去找迭代器和next方法的时候发现,完全换了一套,所以自然不会像这样报错,那么他是怎么处理多线程操作的场景的呢
ConcurrentHashMap是通过synchronized + CAS 算法来实现线程安全的
如果去看源码的话,你会发现ConcurrentHashMap里面有很多Unsafe.compareAndSwap+数据类型的写法,这种写法就是利用CAS算法实现无锁化的修改值操作,此算法可以很大程度的减少加锁过程中造成的性能损耗
这个算法大概就是不断地去用内存中的变量值与代码预期的变量值是否相同,如果是一样的就会修改成功,如果不一样就会拒绝执行修改,用这种方式去判断当前线程中是否是最新的值,若不是则可能会覆盖其他线程的结果
正因此算法的判断方式,如果某个线程将值修改然后又改回去了,该算法仍然会认为这是最新值没有被改过
而通过观察源码发现,在操作Node相关对象时,会用synchronized将对象锁住
标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
