首页 > 极客资料 博客日记
如何判断数据库和对象存储是否被 JuiceFS 使用?
2024-08-16 15:00:06极客资料围观22次
随着使用 JuiceFS 的时间越来越长,一些用户已经用多种数据库和对象存储创建了很多的 JuiceFS 文件系统。有些是纯云端的,有些是纯本地的,有些则是本地与云端结合的。它们当中有一些是存储了文件的,而有一些则只是测试目的临时创建的。多个文件系统混合在一起使用难免会混淆,特别是在同一个数据库实例中创建多个文件系统时会更为明显。
比如在一个 Redis 实例的 0 号数据库和 1 号数据库都创建了文件系统,其中一个是正常使用的,另一个是测试用的,当需要删除测试用的文件系统时,就可能会误删正常使用的文件系统。
在这篇文章会分享一些解决类似问题的日常管理技巧,希望能够帮助到更多的 JuiceFS 用户。
前置知识
在开始之前,先介绍一些 JuiceFS 的基本概念,以便大家更好地理解这些技巧。
如下图,JuiceFS 采用的是一种数据与元数据分离存储的技术架构,数据存储在对象存储中,元数据存储在数据库中。
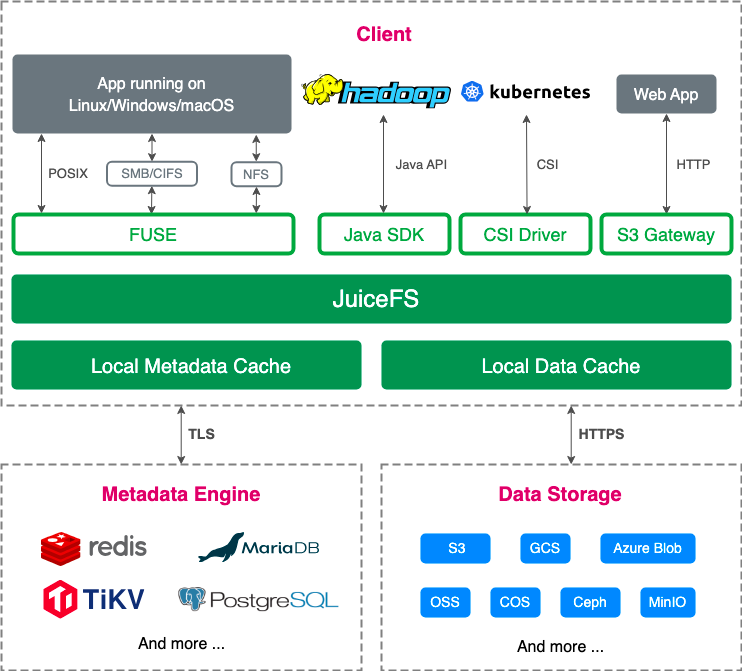
从管理的角度来说,这就涉及到数据库和对象存储两个部分的管理。
情景一:数据库被 JuiceFS 使用了吗?
如果你也像我一样喜欢尝试用不同的数据库作为 JuiceFS 的元数据引擎,那么你可能会遇到这样的情况:有很多数据库,但不确定哪个数据库被 JuiceFS 使用。
对于这种情况,无外乎两种判断方法:
- 用 JuiceFS 客户端执行检查;
- 用数据库客户端执行检查。
两种方法都能用来判断,只是有些数据库更适合用第一种方法,有些数据库更适合用第二种方法。
适合用 JuiceFS 客户端检查的数据库
对于 SQLite3、Badger 这样的单机数据库,直接用 JuiceFS 客户端检查更合适。因为一个数据库只对应一个 JuiceFS 文件系统,所以只要 JuiceFS 客户端能够连接到数据库,就能够检查出这个数据库是否被 JuiceFS 使用。
例如,在我本地电脑的某个目录中发现了一个名为 my.db 的文件,我现在不确定它究竟是 JuiceFS 文件系统的元数据,还是其他应用的数据库。这时,我可以使用 JuiceFS 客户端的 status 子命令来检查:
juicefs status sqlite3://my.db
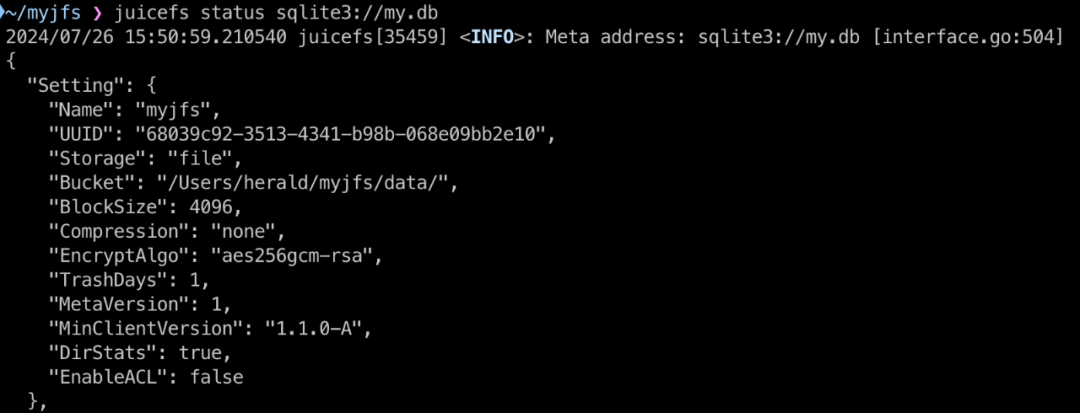
从命令输出的 JSON 中,包含文件系统的名称、UUID、存储类型、对象存储等信息,可以确定这个数据库是一个 JuiceFS 文件系统的的元数据引擎。
如果没有输出 JSON 信息,并显示 database is not formatted,那么这个就不是 JuiceFS 使用的元数据引擎。

与 SQLite3 类似,Badger 也是一个单机数据库,但它的数据库不是单个文件,而是一个目录。
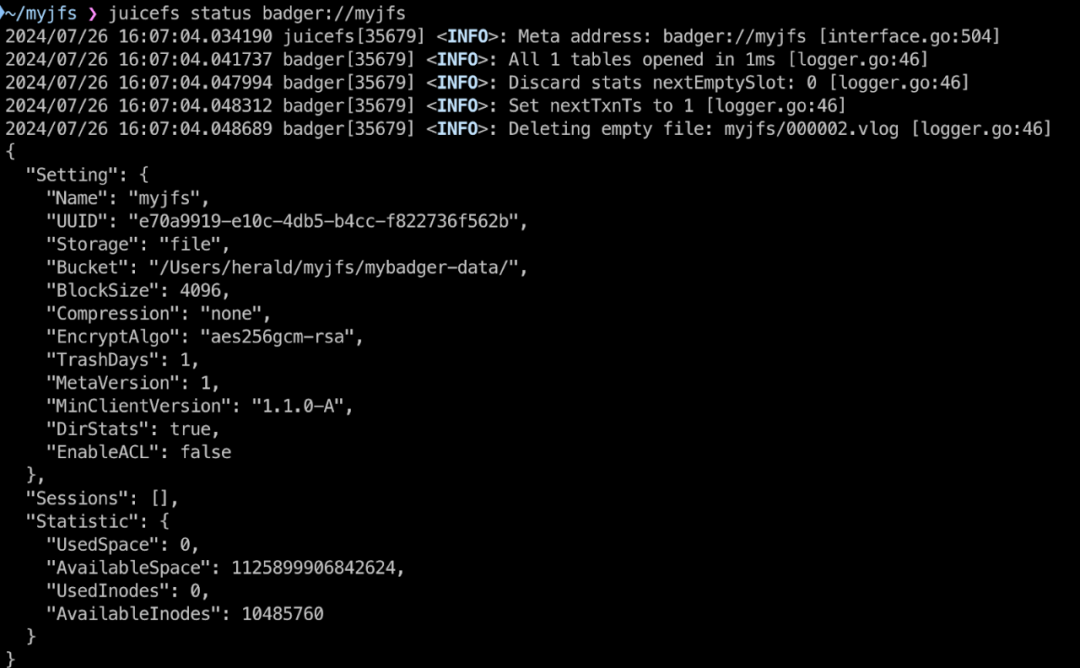
比如,我在本地发现一个名为 myjfs 的目录,时间久远已经不记得它究竟是一个普通的目录,还是 badger 数据库目录。这时,我可以使用 JuiceFS 客户端的 status 子命令来检查:
juicefs status badger://myjfs
适合用数据库客户端检查的数据库
虽然完全可以用 JuiceFS 客户端进行检查,但在数据库很多,以及记不得有哪些数据库的情况下,用数据库客户端检查网络数据库会更为直观方便。
Redis
默认情况下,一个 Redis 实例有编号为 0~15 共计 16 个数据库。如果之前没有在备忘本中明确记录每个数据库的用途,那么时间久了再次要用到的时候,就很难区分哪个数据库是 JuiceFS 使用的。
比如,我有以下 Redis 实例:
| 项 | 值 |
|---|---|
| 地址 | 192.168.1.88 |
| 端口 | 6379 |
| 密码 | password |
我不确定哪个数据库用于 JuiceFS,甚至不确定是否有数据库用于 JuiceFS。这时,最简单的办法就是使用 redis-cli 客户端连接到 Redis 实例,逐一对每个数据库执行检查:
# 连接到 Redis 实例
redis-cli -h 192.168.1.88 -p 6379 -a password
# 检查哪些数据库存储了数据
192.168.1.88> info keyspace
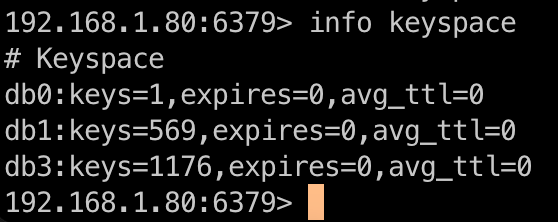
通过 info keyspace 命令,可以看当前实例的 db0、db1 和 db3 都存储了数据,接下来就可以依次对这些数据库执行 get setting 检查是否是 JuiceFS 使用的数据库。
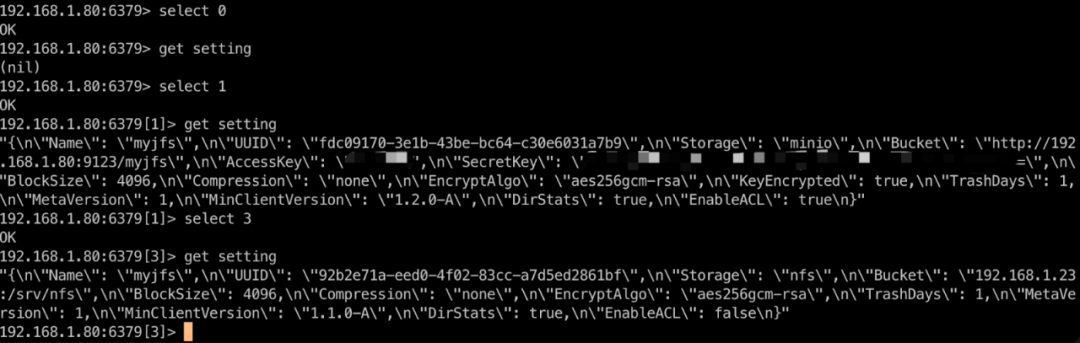
如图所示,db0 没有 JuiceFS 的信息,说明它不是 JuiceFS 使用的数据库。db1 和 db3 都包含 JuiceFS 的信息,说明它们是 JuiceFS 使用的数据库。
Postgres、MySQL、MariaDB
对于这三种数据库,有很多图形化客户端工具可以直接使用,比如 pgAdmin、Adminer、Navicat 等,可以直观地显示数据库中的表、数据等信息。
笔者相对更喜欢使用 Adminer,它是一个非常轻量级的数据库管理工具,可以直接通过 Docker 部署,通过浏览器访问,同时支持上述三种数据库。
假设在本地电脑上已经安装了 Docker,那么可以通过以下命令来部署 Adminer:
docker run -d -p 8080:8080 --name adminer adminer
部署完成后就可以通过浏览器访问 http://localhost:8080 来使用 Adminer。
以 Postgres 数据库为例,连接到 Postgres 数据库后,可以看到数据库中的表、数据等信息。
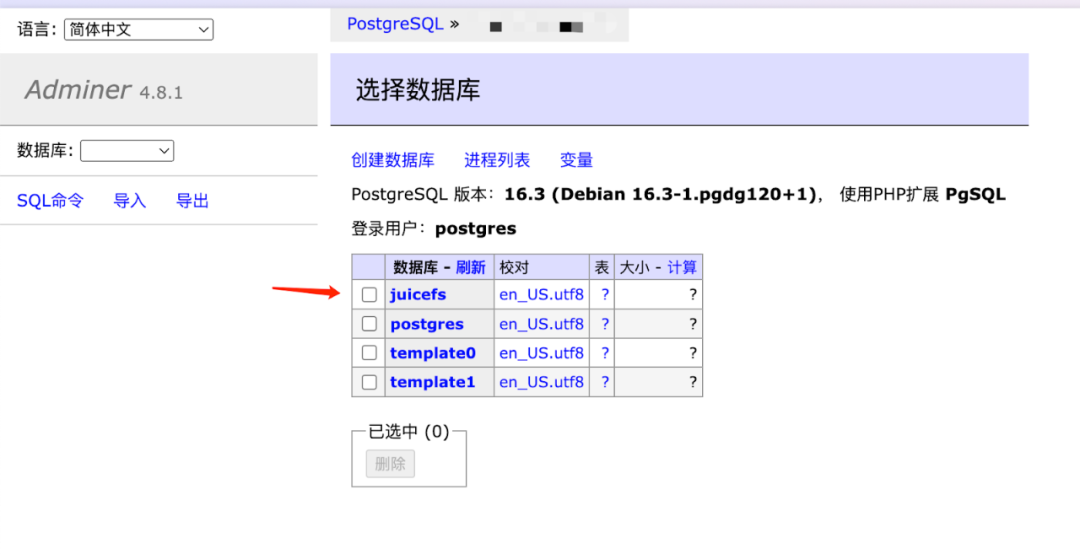
在数据库列表中,如果不确定哪个数据库是 JuiceFS 使用的,可以逐一点击进入数据库,查看其中的表。
如下图,JuiceFS 的表名称通常是以 jfs_ 开头的。
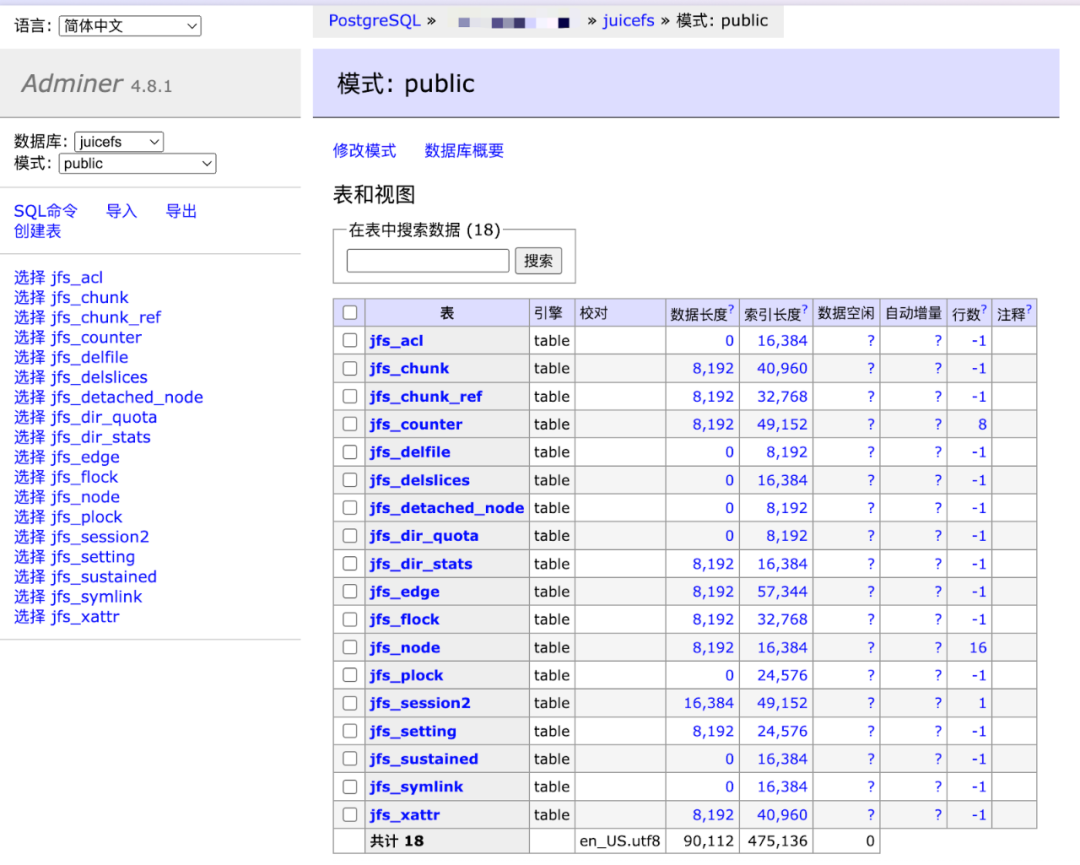
MySQL、MariaDB 等数据库的操作类似,访问时只需要在 Adminer 登录界面中据实选择即可。
另外,JuiceFS 还支持其他数据库,比如 TiKV、etcd、FoundationDB 等,检查它们是否用于 JuiceFS 的方法都是类似的,这里不再赘述。
情景二:对象存储被 JuiceFS 使用了吗?
对于 JuiceFS 文件系统来说,元数据引擎记录着所有文件的信息,对象存储则是保存着所有实际的文件。二者相辅相成,缺一不可。
从管理的角度来说,只要能够确定 JuiceFS 文件系统的元数据引擎,就能够确定对应的对象存储。
也就是说,只要用 juicefs status 命令扫一下相应的数据库,就能找到这个文件系统关联的对象存储。
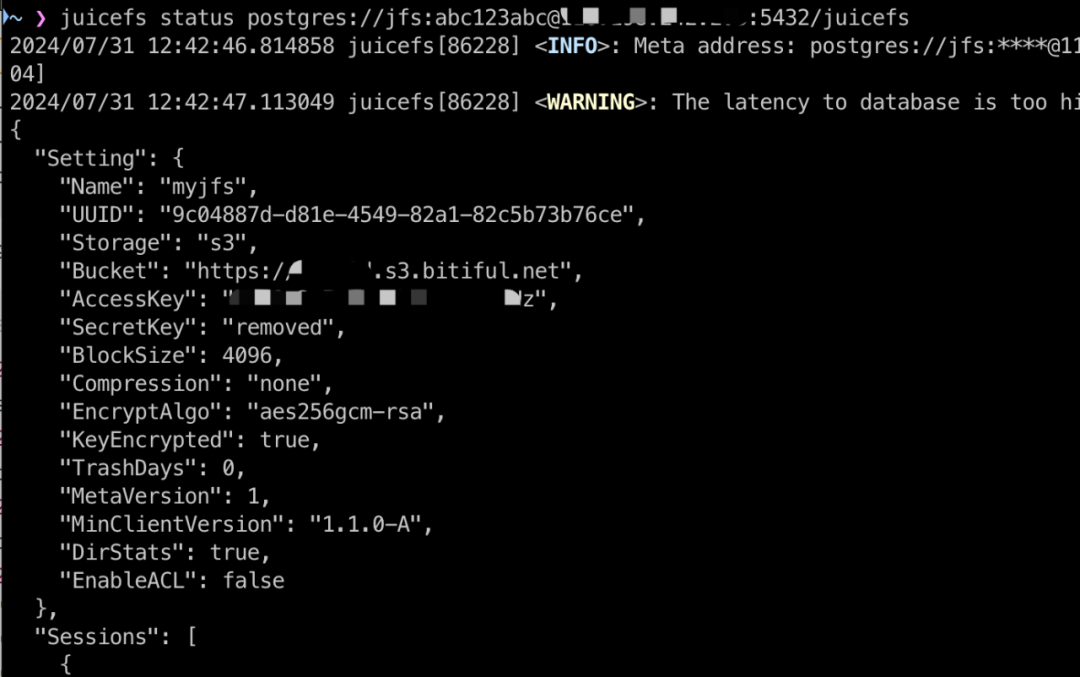
根据输出的信息,在 Bucket 部分可以找到它使用的对象存储。当然,如果你在同一个云平台上有多个账号,最好还是从云平台的文件管理器中逐一查看 Bucket 内容。
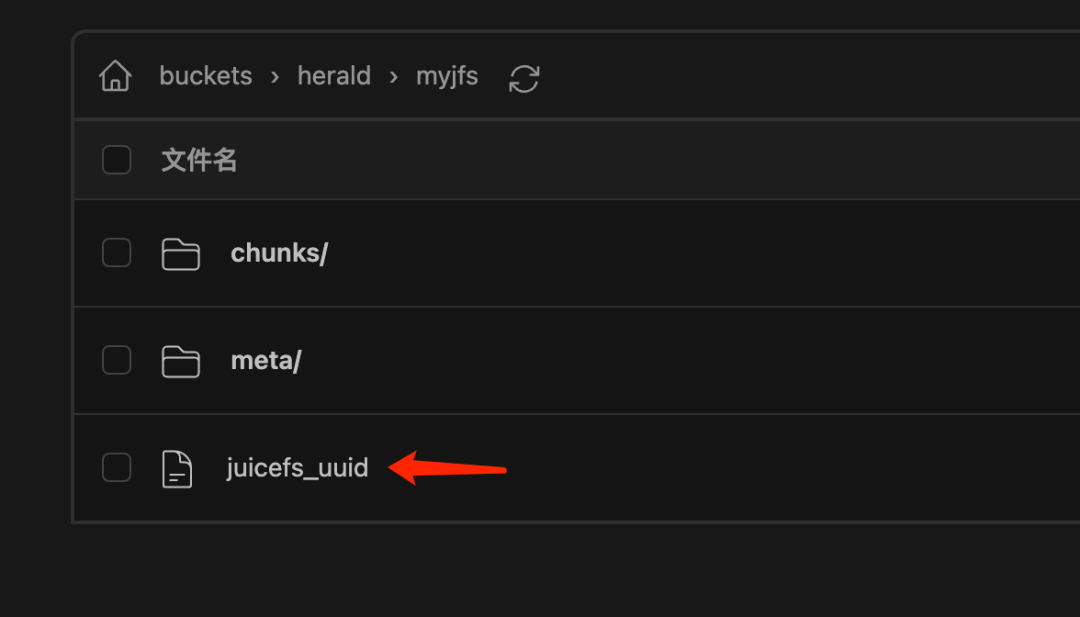
如图所示,JuiceFS 会在 Bucket 根目录下创建一个与文件系统同名的文件夹作为根目录。打开这个目录,可以看到名为 juicefs_uuid 的文件,它是识别 JuiceFS 文件系统的关键。
另外,在文件系统的根目录下,通常还会有 chunks 和 meta 两个目录,分别存储文件的数据块和元数据备份。通过这些特征,就可以判断一个 Bucket 是否属于 JuiceFS 文件系统。
总结
以上两个场景分别介绍了如何判断已有的数据库和对象存储是否被 JuiceFS 使用,掌握了这些技巧,相信读者可以更好地管理 JuiceFS 文件系统,避免误删、误操作等问题。
文章的最后再提供几个创建 JuiceFS 文件系统时的建议:
- 使用单机数据库作为元数据引擎时,数据库命名尽量有意义和简短。这样既方便识别,又方便后续使用;
- 预计会长期使用的文件系统,数据库和 Bucket 建议让 JuiceFS 独享,尽量不要与其他应用共享使用,避免潜在的误操作和使用冲突;
- 为文件系统定义一个容易识别的名称,有助于后续管理,比如在名称中添加 jfs 词缀 my-jfs、test-jfs 等。
如果你有其他问题,欢迎加入 JuiceFS 微信群进行提问,如果你有其他管理技巧,也欢迎分享给我们。
标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
