首页 > 极客资料 博客日记
使用 ollama 在本地试玩 LLM
2024-11-04 02:30:03极客资料围观17次
在 chatGPT 的推动下。LLM 简直火出天际,各行各业都在蹭。听说最近 meta 开源的 llama3 模型可以轻松在普通 PC 上运行,这让我也忍不住来蹭一层。以下是使用 ollama 试玩 llama3 的一些记录。
什么是 llama
LLaMA(Large Language Model Meta AI)是Meta开发的大规模预训练语言模型,基于Transformer架构,具有强大的自然语言处理能力。它在文本生成、问答系统、机器翻译等任务中表现出色。LLaMA模型有多个规模,从几亿到上千亿参数,适用于不同的应用场景。用户可以通过开源平台如Hugging Face获取LLaMA模型,并根据需要进行微调。LLaMA的灵活性和可扩展性使其在自然语言处理领域具有广泛的应用前景。
什么是 ollama
Ollama是一款用于本地安装和管理大规模预训练语言模型的工具。它简化了模型的下载、安装和使用流程,支持多种流行的模型如GPT-4和llama。Ollama通过易于使用的命令行界面和API,帮助用户快速部署和运行自然语言处理任务。它还支持多GPU配置和模型微调,适应各种计算资源和应用需求。总之,Ollama为研究人员和开发者提供了一个高效、灵活的本地化大模型解决方案。
下载 ollama
ollama 官网提供了各种平台的安装包,那么这里选择 windows 系统的。以下是下载地址:https://ollama.com/download
在 windows 上安装
在 windows 上安装那简直太简单了,一路 next 就行了。
安装成功后可以在命令行下执行
ollama -v
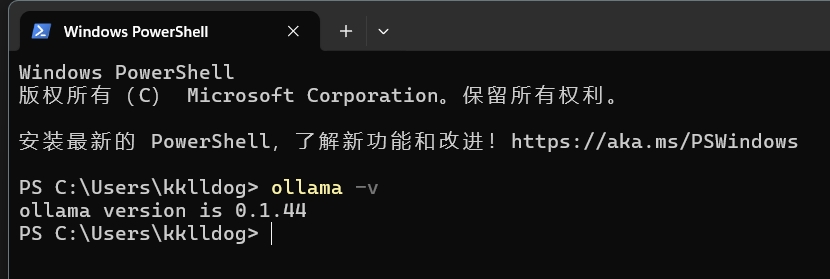
如果能成功打印出版本信息,那么说明你安装成功了。
下载模型并运行
安装好 ollama 之后我们需要把训练好的模型拉到本地,然后才能运行它。
查找 模型
ollama 提供了一个页面供用户查询可以使用的开源模型。
https://ollama.com/search?q=&p=1
可以看到主流的开源 LLM 几乎都能找到。什么 llama3 啊,phi3 啊,国产的 qwen2 啊。让我们点击 llama3 看看详情。
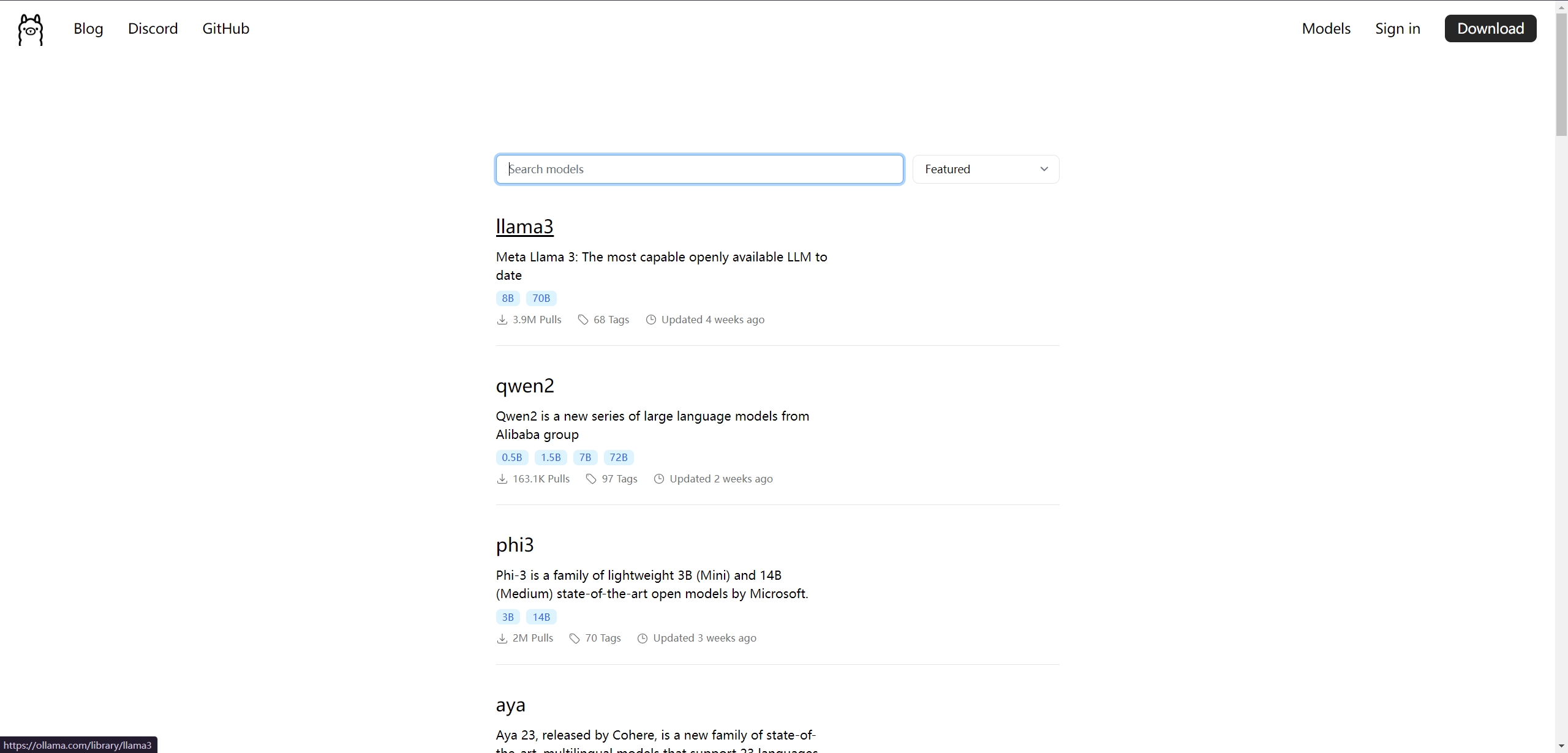
里面可以选模型的参数大小。这里我们选 8b 试一下。模型大小是 4.7 GB。复制右上角的命令并在命令行运行:
ollama run llama3:8b
程序会开始下载模型到本地。这里得夸一下,ollama 是不是在国内接了 CDN,这速度杠杆的,直接跑满了我的千兆网络。
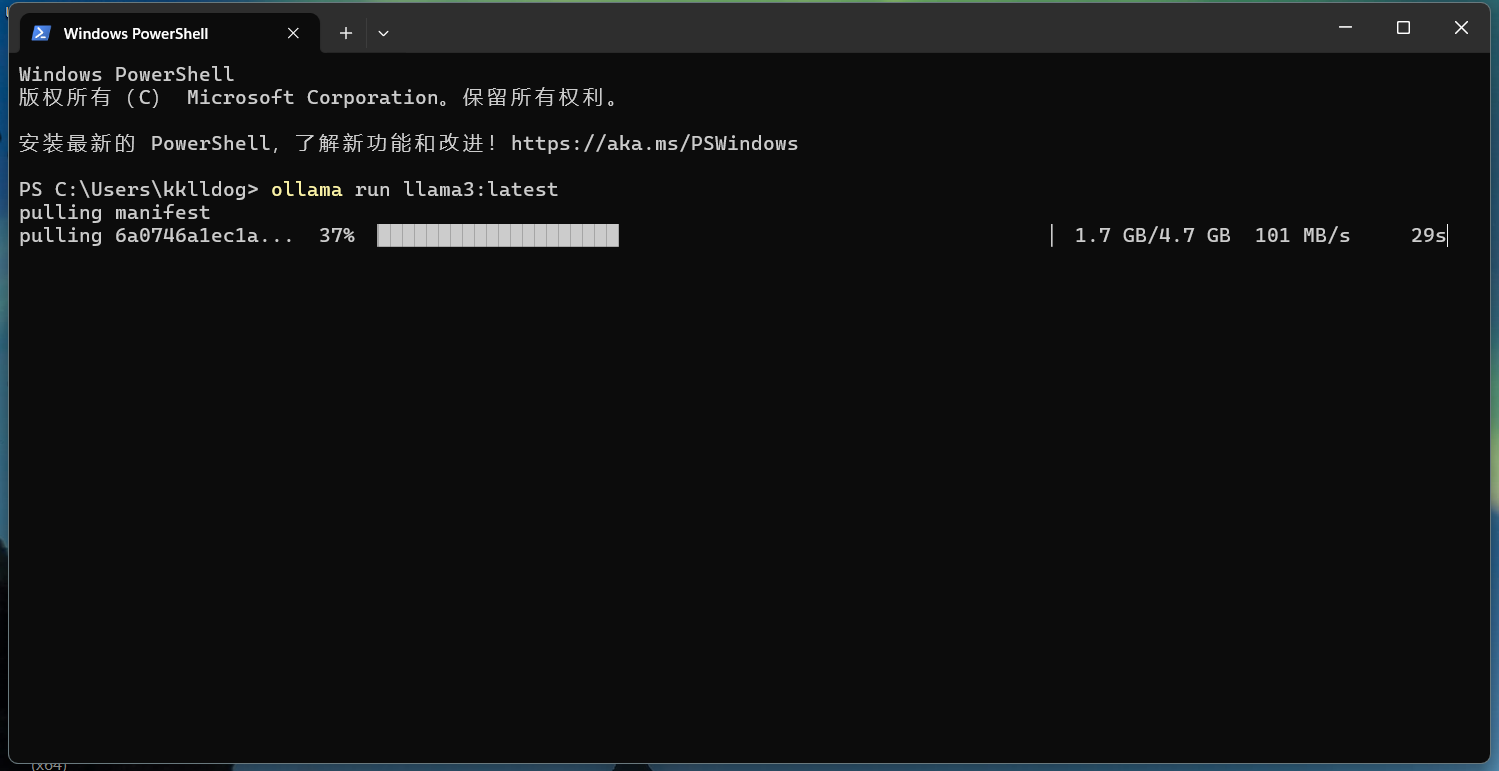
对话
下载完成后命令行就会跳转到对话模型,等待你输入问题。随便先来一个吧。
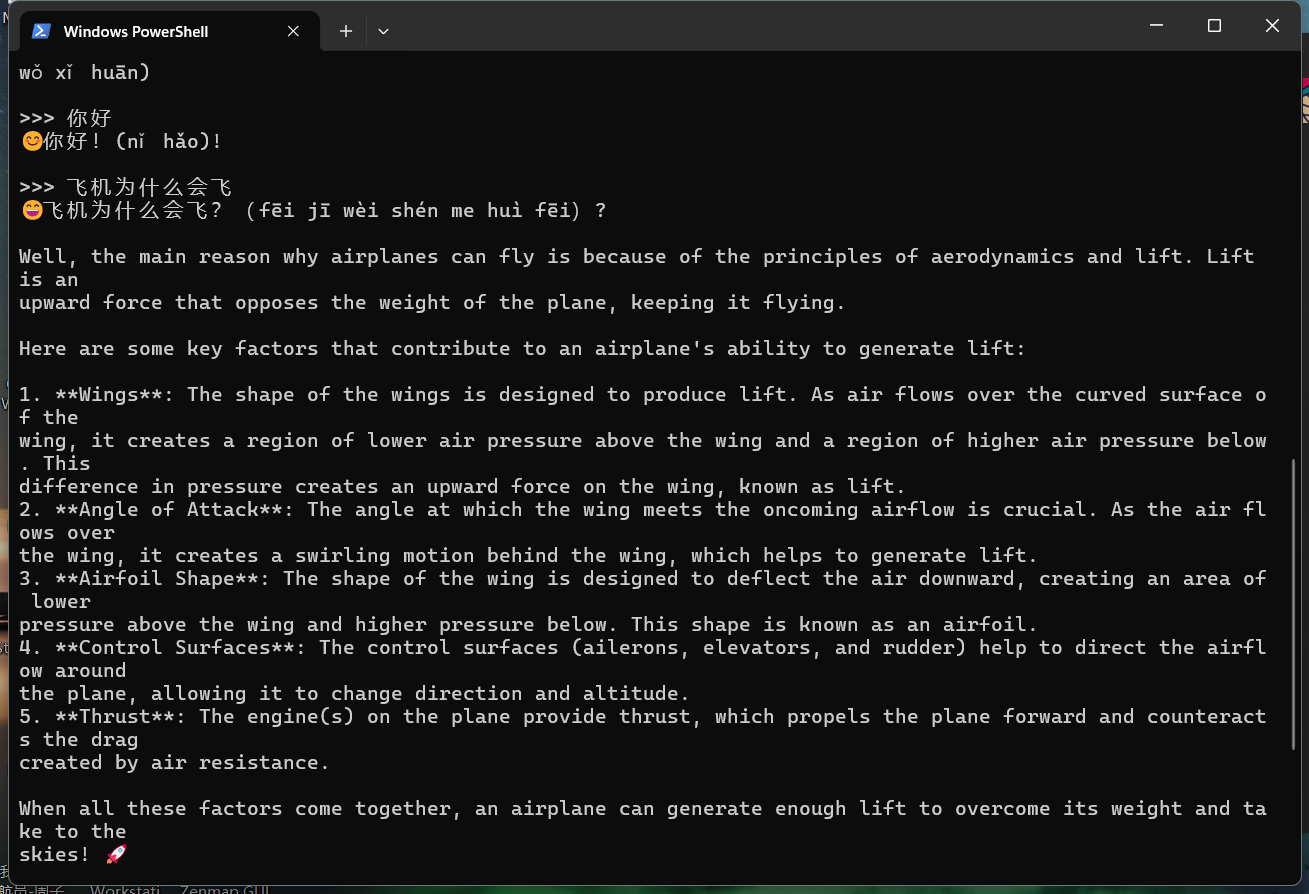
Q:飞机为什么会飞?
A: balabala 一大堆,都是英文。
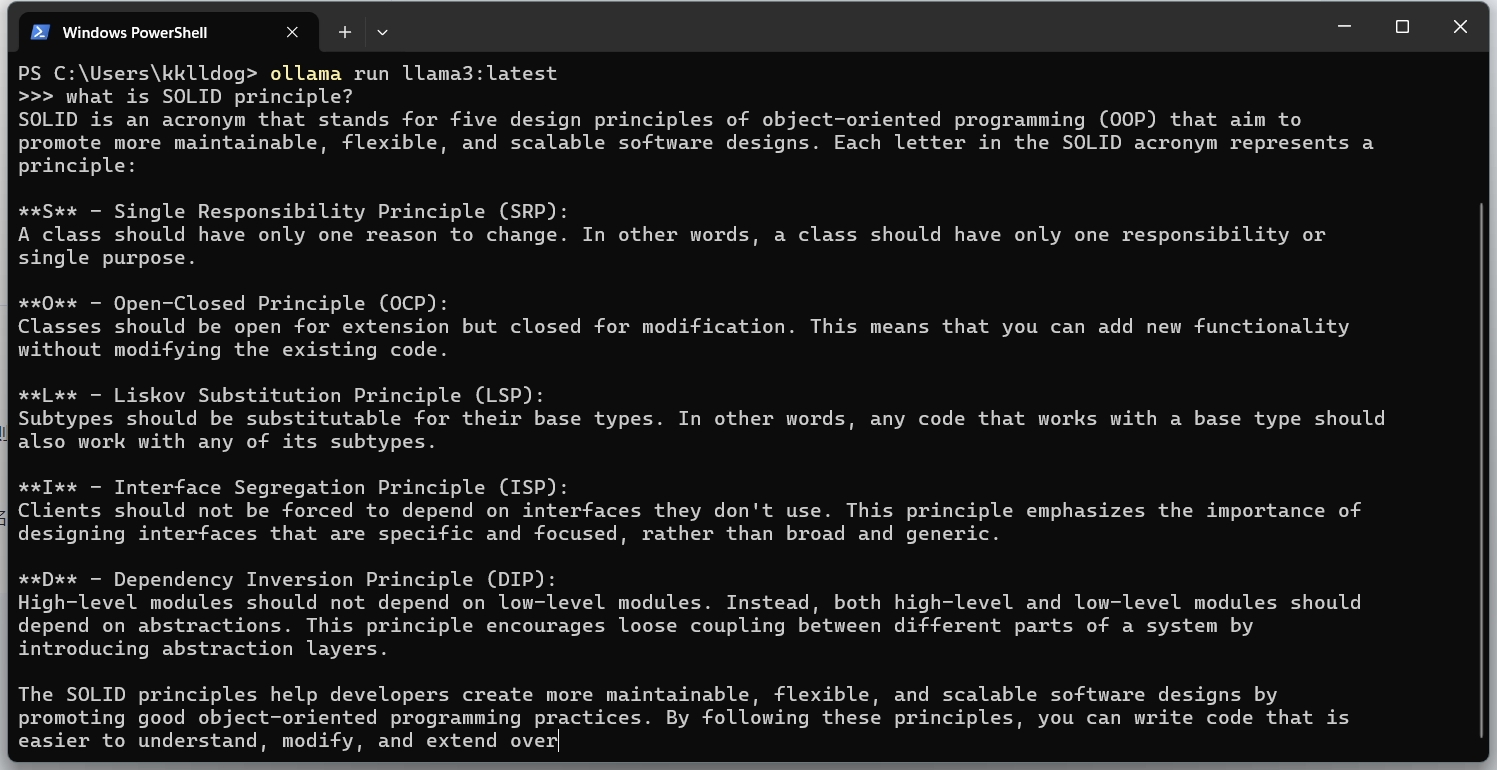
Q: what is SOLID principle?
A:
总结
到这,我们本地运行大模型基本上是初步成功了。简直超级无敌简单,属于有手就行。问题就是本地限制于PC的性能,回答的速度比较慢,大概一秒2-3个单词。CPU大概吃掉50%。当然如果你有 N 卡可能会好很多。内存倒是还好才吃了300多M。好了,下一次我们来试试 open-webui,把本地的模型搞的跟 chatGPT 一样。
标签:
上一篇:数据结构 - 图之代码实现
下一篇:鸿蒙开发案例:指南针
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
