首页 > 极客资料 博客日记
推理优化(1)
2024-11-01 22:00:03极客资料围观13次
吐槽
在连续挖了好几个坑之后,又开了一个新的坑:推理优化。它属于一个llm底层的应用,目的是在操作系统层面来优化llm的执行速度进而优化整个模型。
那闲话少说,我们正式开始。
llm的过程
prefill阶段与decoding阶段
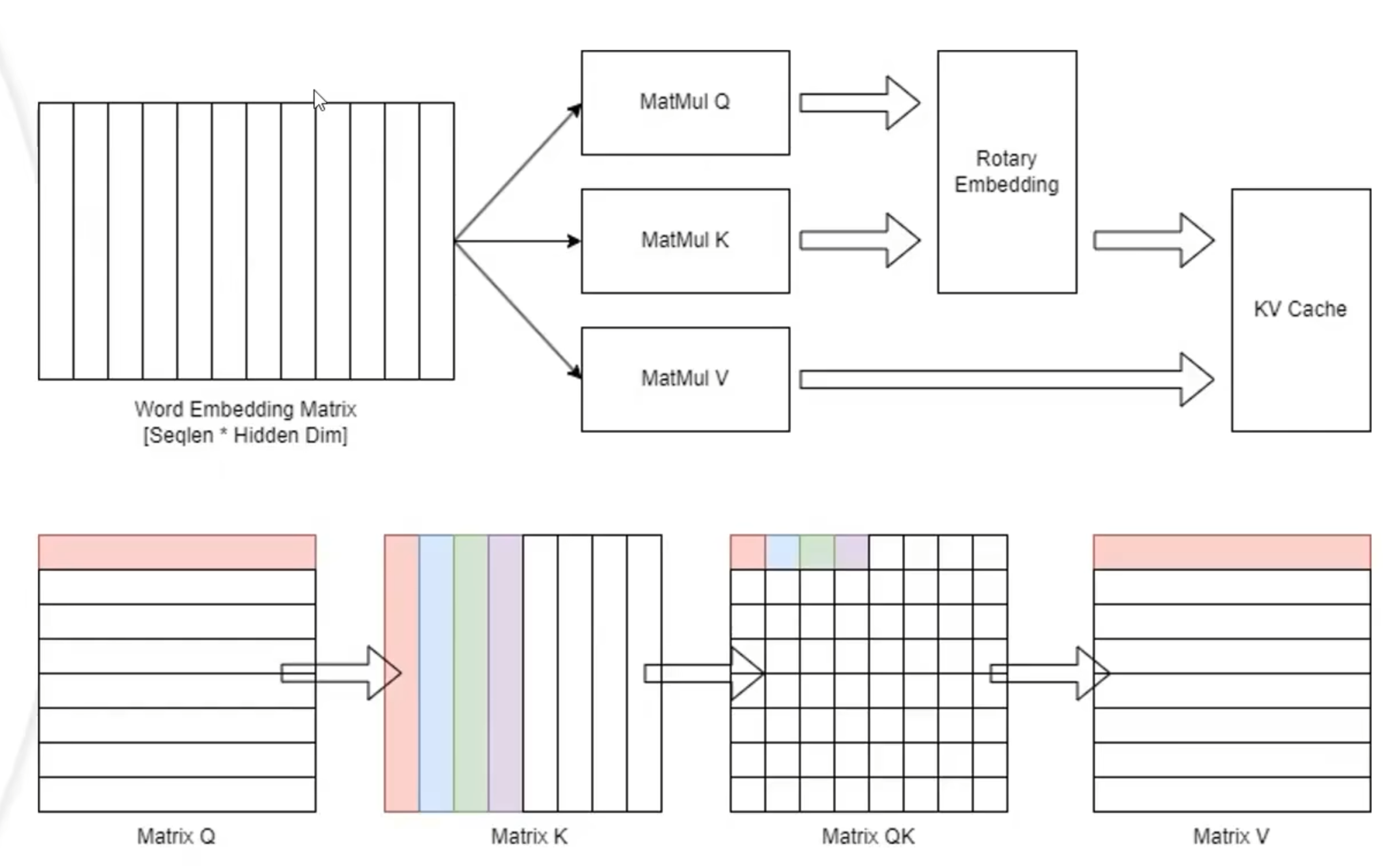
prefill
decoding
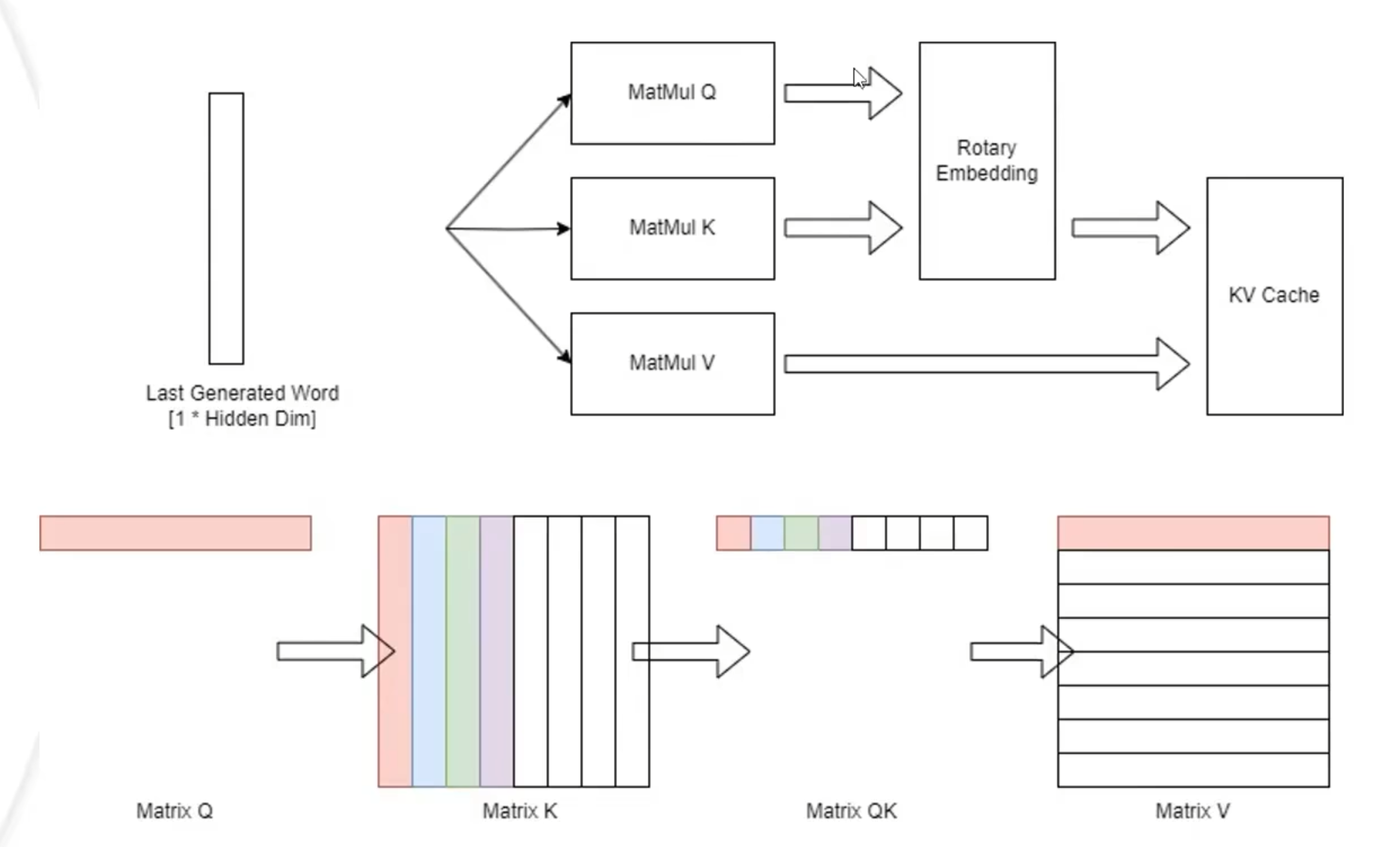
这两者的区别是prefill会先把所有的数据进行拿出来计算,后者只会拿很小一块
推理优化的Benchmark
吞吐量
单位时间内系统能吐出多少个decoding
影响因素:模型优化,输入数据长度
First Token Latency(很重要)
首次prefill阶段所花费的时间
影响因素:输入长度
Latency
生成每个词的间隔
影响因素:输入长度
QPS(每秒请求数)
QPS=K/这K个请求的时间
影响因素:显卡利用率
LLM推理的子过程
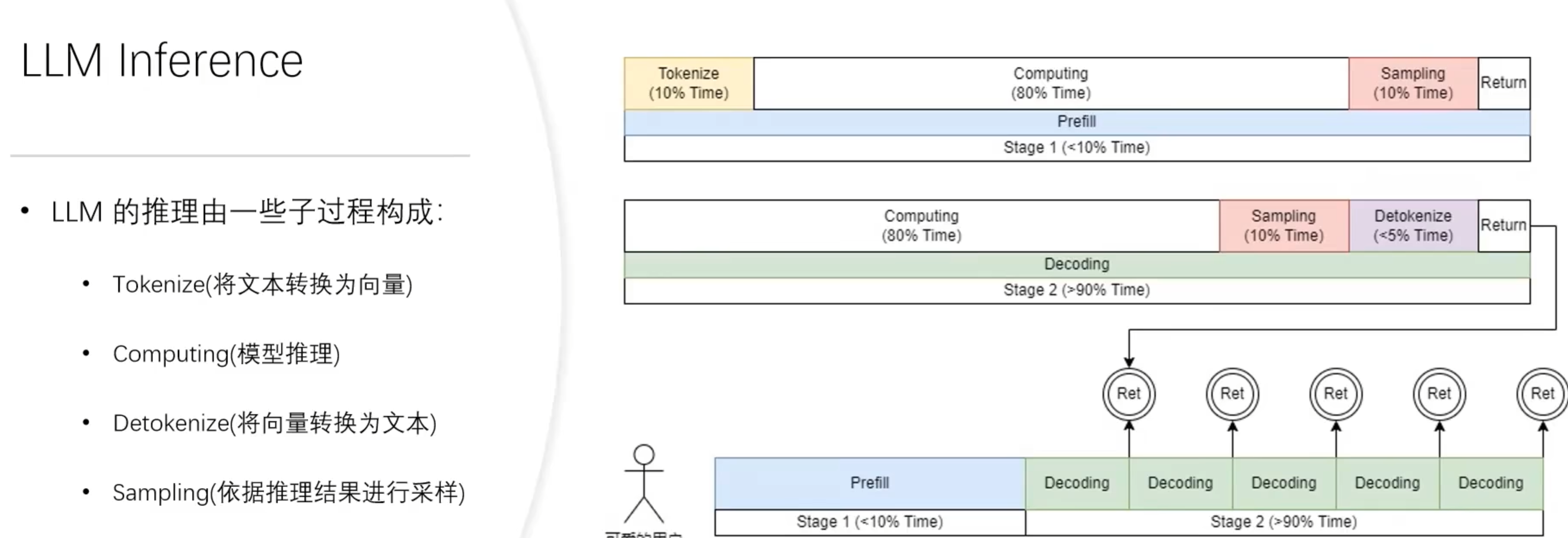
优化
1/流水线前后处理与高性能采样
本质是处理过程中的Tokenize和Detokenize部分可以在cpu中进行处理,这样就不必浪费gpu资源进而提升效率。
2/动态批处理
利用流水线思想优化处理过程,通过将多个用户的过程结合在一起来提升处理速度,具体来说在self Attention层分成了Flash attention和Decoding attention两个部分一起处理merge step。
3/Cache现存管理
过去的cache是直接给每一个用户分配一个固定大小的内存,也有优化版本将用户的信息切块来分配,都是存在问题的。ppl中采用的VM Allocator在过去的cache基础上做了修改,会根据用户过去的信息来做一个预测长度。这样可以有效的减少浪费
4/KV Cache量化
Q:什么是量化?
A:将浮点数表示的数据转换为更小的数据类型,如整数或固定点数,从而减少存储空间和计算开销。

KV缓存决定了服务器能服务的用户数量,优化缓存就是提升性能
应用在self attation,K,V三个层中
5/矩阵乘法量化
矩阵乘法在模型中花费占比70%以上
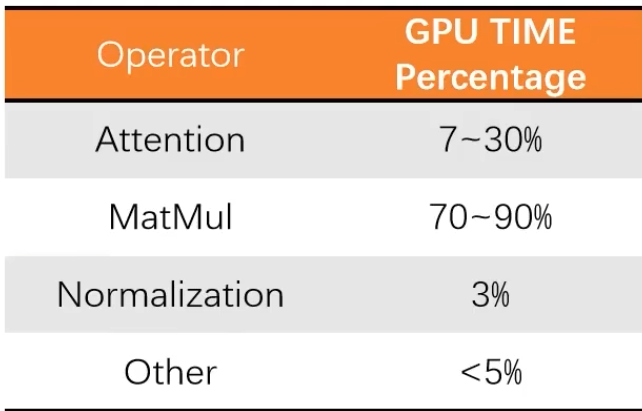
量化大体方向
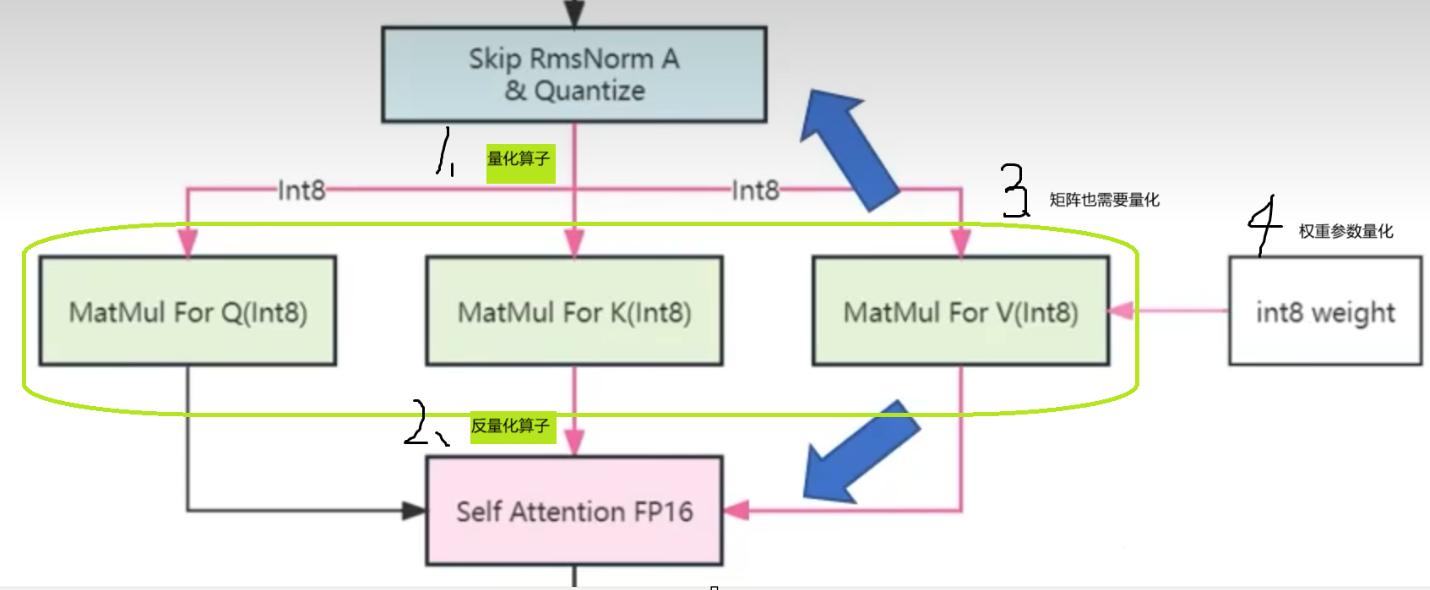
int8 VS int4
int8相比于fp16 加载权重减半,计算时间减半。
int4加载权重会减少的更多,但会多一个解量化的时间,且不减半计算时间。
在服务器中多用int8是因为解量化的时间与计算时间正相关,而服务器中计算占比较大。
标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
