首页 > 极客资料 博客日记
python 爬虫如何爬取动态生成的网页内容
2024-10-31 13:30:04极客资料围观13次
极客之家推荐python 爬虫如何爬取动态生成的网页内容这篇文章给大家,欢迎收藏极客之家享受知识的乐趣
--- 好的方法很多,我们先掌握一种 ---
【背景】
对于网页信息的采集,静态页面我们通常都可以通过python的request.get()库就能获取到整个页面的信息。
但是对于动态生成的网页信息来说,我们通过request.get()是获取不到。
【方法】
可以通过python第三方库selenium来配合实现信息获取,采取方案:python + request + selenium + BeautifulSoup
我们拿纵横中文网的小说采集举例(注意:请查看网站的robots协议找到可以爬取的内容,所谓盗亦有道):
思路整理:
1.通过selenium 定位元素的方式找到小说章节信息
2.通过BeautifulSoup加工后提取章节标题和对应的各章节的链接信息
3.通过request +BeautifulSoup 按章节链接提取小说内容,并将内容存储下来
【上代码】
1.先在开发者工具中,调试定位所需元素对应的xpath命令编写方式
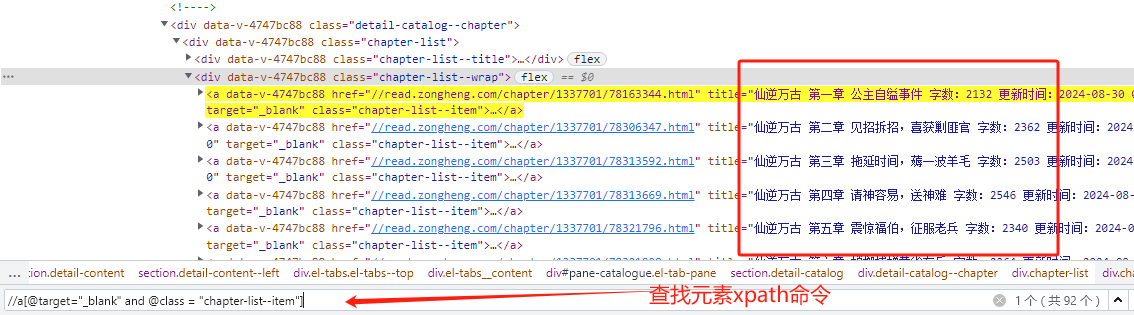
2.通过selenium 中find_elements()定位元素的方式找到所有小说章节,我们这里定义一个方法接受参数来使用
def Get_novel_chapters_info(url:str,xpath:str,skip_num=None,chapters_num=None): # skip_num 需要跳过的采集章节(默认不跳过),chapters_num需要采集的章节数(默认全部章节) # 创建Chrome选项(禁用图形界面) chrome_options = Options() chrome_options.add_argument("--headless") driver = webdriver.Chrome(options=chrome_options) driver.get(url) driver.maximize_window() time.sleep(3) # 采集小说的章节元素 catalogues_list = [] try: catalogues = driver.find_elements(By.XPATH,xpath) if skip_num is None: for catalogue in catalogues: catalogues_list.append(catalogue.get_attribute('outerHTML')) driver.quit() if chapters_num is None: return catalogues_list else: return catalogues_list[:chapters_num] else: for catalogue in catalogues[skip_num:]: catalogues_list.append(catalogue.get_attribute('outerHTML')) driver.quit() if chapters_num is None: return catalogues_list else: return catalogues_list[:chapters_num] except Exception: driver.quit()
3.把采集到的信息通过beautifulsoup加工后,提取章节标题和链接内容
# 获取章节标题和对应的链接信息 title_link = {} for each in catalogues_list: bs = BeautifulSoup(each,'html.parser') chapter = bs.find('a') title = chapter.text link = 'https:' + chapter.get('href') title_link[title] = link
4.通过request+BeautifulSoup 按章节链接提取小说内容,并保存到一个文件中
# 按章节保存小说内容 novel_path = '小说存放的路径/小说名称.txt' with open(novel_path,'a') as f: for title,url in title_link.items(): response = requests.get(url,headers={'user-agent':'Mozilla/5.0'}) html = response.content.decode('utf-8') soup = BeautifulSoup(html,'html.parser') content = soup.find('div',class_='content').text # 先写章节标题,再写小说内容 f.write('---小西瓜免费小说---' + '\n'*2) f.write(title + '\n') f.write(content+'\n'*3)
版权声明:本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
