首页 > 极客资料 博客日记
VictoriaMetrics 中文教程(10)集群版介绍
2024-10-29 08:00:04极客资料围观13次

VictoriaMetrics 中文教程系列文章:
- VictoriaMetrics 中文教程(01)简介
- VictoriaMetrics 中文教程(02)安装
- VictoriaMetrics 中文教程(03)如何配置 Prometheus 使其把数据远程写入 VictoriaMetrics
- VictoriaMetrics 中文教程(04)对接 Grafana 同时介绍 vmui
- VictoriaMetrics 中文教程(05)对接各类监控数据采集器
- VictoriaMetrics 中文教程(06)容量规划
- VictoriaMetrics 中文教程(07)高可用(High availability)方案
- VictoriaMetrics 中文教程(08)VictoriaMetrics 的存储
- VictoriaMetrics 中文教程(09)VictoriaMetrics 18 条 Troubleshooting 建议和提示
集群版简介
VictoriaMetrics 集群版也是开源的,但是维护更复杂,毕竟组件更多。如果数据量低于每秒一百万个数据点,建议使用单节点版本,而不是集群版本。单节点版本可以完美地适应 CPU 核心数、RAM 和可用存储空间。与集群版本相比,单节点版本更易于配置和操作,因此在选择集群版本之前请三思。
突出的功能
- 支持单节点版本的所有功能。
- 性能和容量水平扩展。
- 支持时间序列数据的多个独立命名空间(又称多租户)。
- 支持复制 replication。
VictoriaMetrics 架构概览
VictoriaMetrics 集群由以下服务组成:
- vmstorage - 存储原始数据并返回给定标签过滤器在给定时间范围内的查询数据
- vminsert - 接受提取的数据并根据指标名称及其所有标签的一致性哈希将其分布在 vmstorage 节点之间
- vmselect - 通过从所有配置的 vmstorage 节点获取所需数据来执行查询
每个服务都可以独立扩展,并且可以在最合适的硬件上运行。vmstorage 节点彼此不了解,彼此不通信,也不共享任何数据。这是一个无共享架构。它提高了集群可用性,并简化了集群维护以及集群扩展。
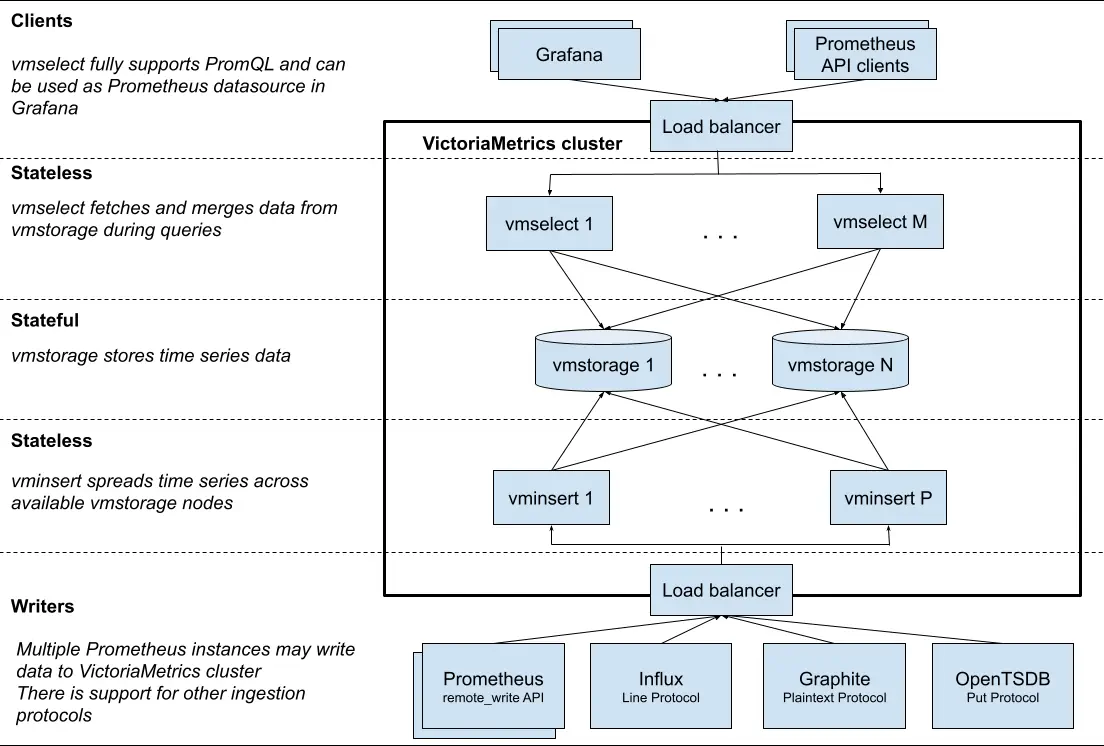
请注意,尽管 vmselect 是无状态的,但仍需要一些磁盘空间(几 GB)用于临时缓存。有关更多详细信息,请参阅
-cacheDataPath命令行标志。
多租户
VictoriaMetrics 集群支持多个相互隔离的租户(又称命名空间)。租户通过 accountID 或 accountID:projectID 进行标识,这些标识放在写入和读取的请求 URL 中。有关 VictoriaMetrics 租户的一些事实:
- 每个 accountID 和 projectID 都由
[0 .. 2^32)范围内的任意 32 位整数标识。如果缺少 projectID,则自动将其分配为 0。预计有关租户的其他信息(例如身份验证令牌、租户名称、限制、会计等)将存储在单独的关系数据库中。此数据库必须由位于 VictoriaMetrics 集群前面的单独服务(例如 vmauth 或 vmgateway)管理。 - 当第一个数据点写入给定租户时,会自动创建租户。
- 所有租户的数据均匀分布在可用的 vmstorage 节点上。当不同租户的数据量和查询负载不同时,这可保证 vmstorage 节点之间的负载均匀。
- 数据库性能和资源使用情况与租户数量无关。它主要取决于所有租户中活跃时间序列的总数。如果某个时间序列在过去一小时内至少收到一个样本,或者在过去一小时内受到查询的影响,则该时间序列被视为活跃时间序列。
- 可以通过
http://<vmselect>:8481/admin/tenantsurl获取已注册租户列表。 - VictoriaMetrics 通过指标公开各个租户统计数据。
很多人知道,集群版本的读写地址是:
- 读:
http://{vmselect}:8481/select/0/<suffix>,比如http://{vmselect}:8481/select/0/prometheus/api/v1/query - 写:
http://{vminsert}:8480/insert/0/<suffix>,比如http://{vminsert}:8480/insert/0/prometheus/api/v1/write
这里的 0 是 accountID,<suffix> 是具体的路径。0 表示 accountID 为 0,projectID 也为 0,即默认租户。
集群版启动
最小集群必须包含以下节点:
- 具有
-retentionPeriod和-storageDataPath命令行参数的单个 vmstorage 节点 - 带有
-storageNode=<vmstorage_host>的单个 vminsert 节点 - 带有
-storageNode=<vmstorage_host>的单个 vmselect 节点
为了实现高可用性,建议为每个服务运行至少两个节点。在这种情况下,当单个节点暂时不可用时,集群将继续工作,其余节点可以处理增加的工作负载。当底层硬件发生故障、软件升级、迁移或其他维护任务期间,该节点可能会暂时不可用。
最好运行许多小型 vmstorage 节点而不是少数大型 vmstorage 节点,因为当某些 vmstorage 节点暂时不可用时,这可以减少剩余 vmstorage 节点上的工作负载增加。
必须在 vminsert 和 vmselect 节点前放置一个 http 负载均衡器,例如 vmauth 或 nginx。它必须根据 url 格式包含以下路由配置:
- 以
/insert开头的请求必须路由到 vminsert 节点上的端口 8480。 - 以
/select开头的请求必须路由到 vmselect 节点上的端口 8481。
可以通过在相应节点上设置 -httpListenAddr 来改变端口。
只读模式
当 -storageDataPath 指向的目录包含的可用空间少于 -storage.minFreeDiskSpaceBytes 时,vmstorage 节点会自动切换到只读模式。vminsert 节点停止向此类节点发送数据,并开始将数据重新路由到剩余的 vmstorage 节点。
当 vmstorage 进入只读模式时,它会将 http://vmstorage:8482/metrics 上的 vm_storage_is_read_only 指标设置为 1。当 vmstorage 未处于只读模式时,该指标设置为 0。
Replication 和数据安全
默认情况下,VictoriaMetrics 建议用户把 -storageDataPath 指向的高可用的底层存储(例如 Google 计算持久磁盘),从而保证数据的持久性。如果由于某种原因无法使用复制的持久持久磁盘,VictoriaMetrics 支持应用程序级复制。
可以通过将 -replicationFactor=N 命令行标志传递给 vminsert 来启用复制。这将指示 vminsert 在 N 个不同的 vmstorage 节点上存储每个摄取样本的 N 个副本。这保证了如果最多 N-1 个 vmstorage 节点不可用,所有存储的数据仍然可供查询。
将 -replicationFactor=N 命令行标志传递给 vmselect,指示它如果在查询期间少于 -replicationFactor 的 vmstorage 节点不可用,则不要将响应标记为部分。
集群必须包含至少 2*N-1 个 vmstorage 节点,其中 N 是复制因子,以便在 N-1 个存储节点不可用时维持新提取数据的给定复制因子。
VictoriaMetrics 以毫秒精度存储时间戳,因此在启用复制时必须将 -dedup.minScrapeInterval=1ms 命令行标志传递给 vmselect 节点,以便它们可以在查询期间对从不同 vmstorage 节点获得的重复样本进行去重。如果从配置相同的 vmagent 实例或 Prometheus 实例将重复数据推送到 VictoriaMetrics,则必须根据去重文档将 -dedup.minScrapeInterval 设置为 scrape 配置中的 scrape_interval。
请注意,复制无法避免灾难,因此建议定期进行备份。
请注意,复制会增加资源使用率(CPU、RAM、磁盘空间、网络带宽),最多可增加 -replicationFactor=N 倍,因为 vminsert 将传入数据的 N 份副本存储到不同的 vmstorage 节点,而 vmselect 需要在查询期间对从 vmstorage 节点获得的复制数据进行重复数据删除。因此,把复制交由 -storageDataPath 指向的底层复制持久存储(如 Google Compute Engine 持久磁盘)更具成本效益,这样可以防止数据丢失和数据损坏。它还提供一致的高性能,并且可以在不停机的情况下调整大小。基于 HDD 的持久磁盘应该足以满足大多数用例。建议在 Kubernetes 中使用持久的复制持久卷。
Deduplication
VictoriaMetrics 的集群版本以与单节点版本相同的方式支持数据重复数据删除。唯一的区别是,当同一时间序列的样本和样本重复最终位于不同的 vmstorage 节点上时,无法保证重复数据删除。这可能发生在以下情况下:
- 当添加/删除 vmstorage 节点时,时间序列的新样本将被重新路由到另一个 vmstorage 节点;
- 当 vmstorage 节点暂时不可用时(例如,在重新启动期间)。然后新的样本被重新路由到剩余的可用 vmstorage 节点;
- 当 vmstorage 节点没有足够的容量来处理传入的数据流时,vminsert 会将新样本重新路由到其他 vmstorage 节点。
建议为 vmselect 和 vmstorage 节点设置相同的 -dedup.minScrapeInterval 命令行标志值,以确保查询结果的一致性,即使存储层尚未完成重复数据删除。
总结
VictoriaMetrics 集群版相比单机版,更适合大规模的监控数据存储和查询。但是,集群版的维护和运维成本更高,需要更多的硬件资源。在选择集群版之前,请三思。VictoriaMetrics 支持 replication,挂掉部分节点不影响数据安全,不过,建议不要开启,而是交由云盘等底层存储来保证数据的持久性。如果没有条件使用云存储,再考虑开启 replication。
标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
