首页 > 极客资料 博客日记
Turbo Sparse:关于LLM稀疏性的探索
2024-08-10 23:00:03极客资料围观24次
极客之家推荐Turbo Sparse:关于LLM稀疏性的探索这篇文章给大家,欢迎收藏极客之家享受知识的乐趣
本文地址:https://www.cnblogs.com/wanger-sjtu/p/18352898
关于llama稀疏性的观察
llama原始模型的FFN计算过程为:
\[f(x) = \text{silu}(xW_{Gate}) \odot xW_{UP} \times W_{Down}
\]
class FeedForward(nn.Module):
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
| Model | Sparisty |
|---|---|
| Llama-2-7B | 40% |
| ReLULlama-7B | 67% |
| ShiftedReLULlama-7B | 71% |
论文统计首层transformer block FFN层的稀疏性质,原生FFN的稀疏性仅有40%,激活函数由silu替换为Relu后可以达到67%,而ShiftedReLU可进一步提高到71%。
从FFN层的计算上来看,表面上是Gate部分作为门控控制了计算的稀疏性,实际上Up、Gate共同控制了计算的稀疏性,所以很自然的就引出了drelu的方案
\[\text{Combined dReLU} (x) := max(0, xW_{gate} ) \odot max(0, xW_{up} )
\]
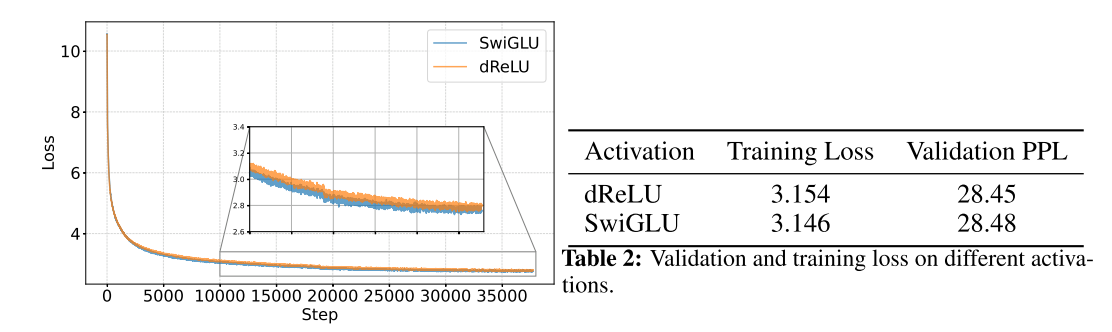
从训练过程上来看,替换以后收敛性没有影响,结果的评价指标上也没有太大影响。
下一步就是进一步评价下修改以后得稀疏度了。这里没有直接用两个mask的交集,而是按照topk的方法做了评测
\[\text{Mask}(x) := Top_k(|\text{Combined}(x)|)
\]
\[ \text{Gated-MLP}(x) := (\text{Combined}(x) ∗ \text{Mask}(x))W_{down}
\]
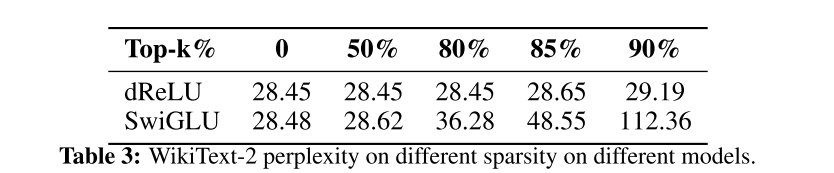
显然效果显著。不影响模型表现的情况下,稀疏到达到了80%,而牺牲一定精度的条件下可以到达90%
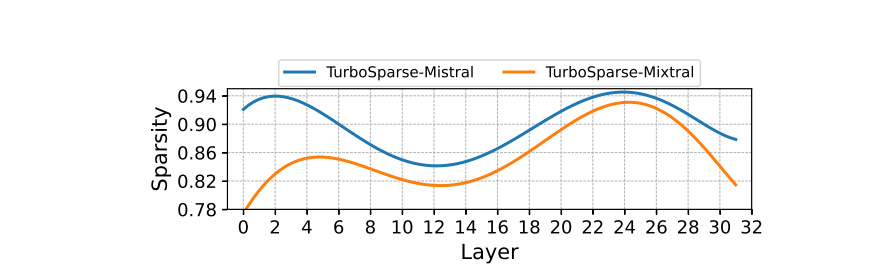
Sparsity of Sparsifi ed Models
版权声明:本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
