首页 > 极客资料 博客日记
HDFS 重要机制之 checkpoint
2024-10-22 14:30:03极客资料围观15次
核心概念
hdfs checkpoint 机制对于 namenode 元数据的保护至关重要, 是否正常完成检查点是评估 hdfs 集群健康度和风险的重要指标
- editslog : 对 hdfs 操作的事务记录,类似于 wal ,edit log文件以 edits_ 开头,后面跟一个txid范围段,并且多个edit log之间首尾相连,正在使用的 edit log 名字为 edits_inprogress_txid(dfs.namenode.edits.dir)
- fsimage:文件系统的元数据,snn会定时合并将内存中的元数据落盘生成新的fsimage,默认会保存两个fsimage文件,文件格式为fsimage_txid(dfs.namenode.name.dir)
- seen_txid:记录了最后一次 checkpoint 或者 edit 回滚(将 edits_inprogress_xxx 文件回滚成一个新的 Edits 文件)之后的 transaction ID。主要用来检查 NameNode 启动过程中 Edits 文件是否有丢失的情况
检查点将从旧的 fsimage 和编辑日志进行合并,创建一个新的 fsimage
checkpoint 触发由三个参数控制
dfs.namenode.checkpoint.period
dfs.namenode.checkpoint.txns
dfs.namenode.checkpoint.check.periodHA 集群的 checkpoint 过程
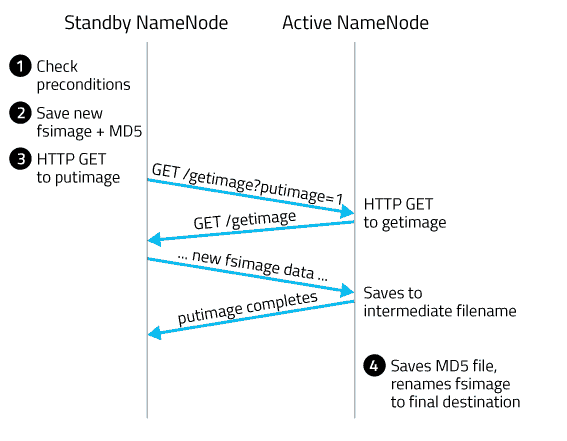
这里 standby namenode 称为 SBNN,active namenode 称为 ANN
- SBNN 查看是否满足创建检查点的条件(距离上次 checkpoint 的时间间隔大于等于 dfs.namenode.checkpoint.period
edits log 中的事务条数达到 dfs.namenode.checkpoint.txns 限制) - SBNN 将内存中当前的状态保存成一个新的文件,命名为fsimage.ckpt_txid。其中 txid 是最后一个 edit log 中的最后一条事务的 ID(transaction ID,不包括 inprogress)。然后为该 fsimage 文件创建一个MD5 文件,并将 fsimage 文件重命名为 fsimage_txid。
- SBNN 向 ANN 发送一条 HTTP GET 请求。请求中包含了 SBNN 的域名,端口以及新 fsimage 的 txid。
ANN 收到请求后,用获取到的信息反过来向 SBNN 再发送一条 HTTP GET 请求,获取新的 fsimage 文件。这个新的 fsimage 文件传输到 ANN 上后,也是先命名为 fsimage.ckpt_txid,并为它创建一个 MD5 文件。然后再改名为 fsimage_txid,checkpoint过程完成。
生产实践
对于大规模的集群,如果长期未成功完成 checkpoint ,那么会积累非常多的 editlog 文件.重启 namenode 的时候,必须要回放 editlog ,以使内存中的目录树恢复到最新状态.回放 editlog 必然是逐个文件来回放的,此时如果积累了大量的 editlog 文件,那么这个过程会长达三个小时以上.增大 namenode 的内存可以适当加快这个过程.
- edit 文件堆积处理
如果长期 edit 日志文件有堆积,可以进入安全模式后,手动运行 saveNamespace 命令来进行一次合并. 但是线上环境中,不能进入安全模式,这个时候可以通过重启 standynamenode 来触发一次 checkpoint
遇到过一次线上问题,由于 ann 锁的问题导致 sbnn 无法 put fsimage 到 ann,重启 sbnn 也无法完成最终完成 checkpoint ,这个时候可以等 sbnn namespace 正常启动后,然后进行一次主备切换,使之前锁住的 ann 变成了 sbnn,然后重启这个节点,此时就能够完成 checkpoint 了,堆积的 edit 文件也能够被清理了
- 手动 checkpoint 方法
hdfs dfsadmin -fs 10.0.0.26:4007 -safemode enter
hdfs dfsadmin -fs 10.0.0.26:4007 -saveNamespace
hdfs dfsadmin -fs 10.0.0.26:4007 -safemode leave
hdfs dfsadmin -safemode forceExit //强制退出安全模式
- 监控 checkpoint
有两个重要指标:
- TransactionsSinceLastCheckpoint 表示距离上次checkpoint的事务数,建议超过3000000 告警
- LastCheckpointTime 上次checkpoint的时间,建议距离当前时间超过12小时告警
- 谨慎重启 NameNode
hdfs 在重启流程需要加载 edit logs,如果 edit logs 遗留有没被注意到的错误, hdfs 将会无法启动完成,导致生产事故
比较常见的原因是:
误删editslog、JournalNode节点有断电、数据目录磁盘占满、网络持续异常等
常见报错如下:
java.io.IOException: Gap in transactions. Expected to be able to read up until at least txid 813248390 but unable to find any edit logs containing txid 363417469可以动态开启DEBUG 日志级别定位报错位置
解决办法:
- 查看其它的JournalNode的数据目录或NameNode数据目录中,有没有连续的该序号相关的连续的edits文件。如果可以找到,复制一个连续的片段到该JournalNode
- 使用namenode recovery 模式 跳过 edits 错误
- 使用 edits viewer 修复错误 edit 文件
- 从 active nn 恢复 standy nn
- 以上如不能解决,只能从fsimage恢复namenode 来上线 namenode
标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
