首页 > 极客资料 博客日记
SIGIR2024| RAREMed: 不放弃任何一个患者——提高对罕见病患者的药物推荐准确性
2024-10-11 23:00:03极客资料围观18次
SIGIR2024| RAREMed: 不放弃任何一个患者——提高对罕见病患者的药物推荐准确性
TLDR:在本文中,我们针对药物推荐模型对罕见病患者推荐精度低的问题,提出了一种新的基于预训练-微调的药物推荐模型框架RAREMed,并提出了两个针对性的预训练任务,来提高模型对患者病情,尤其是罕见病患者病情的表示学习能力,帮助药物推荐模型提高对罕见病患者的推荐准确度,从而提升药物推荐模型的公平性。我们在两个常用的公开数据集上的实验结果显示出我们的方法在药物推荐模型的准确度和公平性方面有着显著优势。
论文地址:https://arxiv.org/abs/2403.17745
代码地址:https://github.com/zzhUSTC2016/RAREMed

引言
随着人工智能的快速发展,其在医疗健康领域的应用得到了越来越多的关注,其中,药物推荐是一个重要的任务,近年来取得了快速的发展。药物推荐任务旨在利用病人的疾病、手术、病史等临床信息,为患者或医生推荐有效、安全的药物组合,减轻医生的工作负担,并减少潜在的医疗失误风险,例如药物误用、不良的药物-药物相互作用等。
现有的药物推荐模型主要关注提高整体的药物推荐准确度,但它们面临的一个普遍问题是公平性问题——对患有罕见病病人的推荐准确率显著低于其他病人,见图1(b)。这主要是由于罕见病在训练数据中出现的次数很少,模型难以学到准确的表达。如图1(a)所示,一少部分疾病出现次数很多,而大多数长尾疾病出现次数很少。另一方面,现有的药物推荐模型将两个关键的输入——疾病(diseases)和手术(procedures)分开建模,导致模型难以捕捉两种输入之间的关联。

图1:(a) 两个常见公开数据集上的疾病编码的长尾分布 (b) 罕见病病人和常见病病人的推荐准确度对比
在这篇工作中,为了解决药物推荐面临的公平性问题,我们利用transformer架构,并提出了两种针对性的预训练任务来提高模型的学习和表达能力。具体来说,模型包含两个预训练任务:序列匹配预测(Sequence Matching Prediction, SMP)和自重构(Self Reconstruction, SR)。序列匹配预测任务使模型可以分辨疾病和手术序列是否属于同一个病人,从而更好地理解病人病情信息中的关联关系。自重构任务使模型可以利用学到的病人表示重建出病人的输入编码,从而更全面地捕捉病人的输入信息。
问题定义
在药物推荐任务中,输入信息通常是EHR(Electronic Health Record, 医疗健康记录),其中包含病人的医疗记录信息\(\mathcal{V}^{(j)} = \{\mathbf{d}^{(j)}, \mathbf{p}^{(j)}, \mathbf{m}^{(j)}\}\),其中\(\mathbf{d}^{(j)} = [d_1, d_2, \cdots, d_x] \in \mathcal{D}\)表示患者所患的疾病,\(\mathbf{p}^{(j)} = [p_1, p_2, \cdots, p_y] \in \mathcal{P}\)表示患者所做的手术,\(\mathbf{m}^{(j)} \in \{0, 1\}^{|\mathcal{M}|}\)表示医生开的药物。除此之外,输入信息还包括药物-药物相互作用关系(DDI Graph, Drug-Drug Interaction Graph),用于约束和评价药物推荐结果中的不良药物相互作用。
药物推荐任务被定义为:给定病人的疾病序列\(\mathbf{d}\)和手术序列\(\mathbf{p}\),以及药物药物相互作用关系图\(\mathbf{A}\),目标是推荐一个药物集合\(\hat{\mathcal{Y}}\),以最大化预测准确率,并尽可能减少不良药物相互作用。
公平的药物推荐任务是指,除了上述药物推荐优化目标之外,还需要模型对患有常见病和罕见病的病人都有相似的推荐准确率,减少模型推荐结果对罕见病病人的不公平性。
罕见病病人特征分析

图2:横坐标为患者最罕见疾病出现次数,纵坐标为患有不同流行度的患者组对应的(a) 疾病数量,(b) 手术数量,(c) 药物数量,(d) 药物流行度,均为平均值
我们将MIMIC-IV数据集中的患者根据所患最罕见疾病的流行度划分为数组,并统计各组内患者的特征,如图2所示,我们有如下两个观察:
Observation 1: 患有罕见病的病人病情更复杂。如图2(a)(b)所示,各患者组内患者所患疾病数量和手术数量随患者疾病流行度增加而下降。
Observation 2: 患有罕见病的病人治疗方案更复杂、更个性化。如图2(c)(d)所示,罕见病患者通常需要更多、更罕见的药物进行治疗。
这些都为罕见病病人的药物推荐提出了更大的挑战。为这些病人提供更准确的药物推荐结果需要更全面地捕捉他们的病情,并提供更全面、更个性化的药物推荐结果。
方法
为了提供更准确、更公平的药物推荐,我们提出了Robust and Accurate REcommendations for Medication (RAREMed)模型,如图3所示。模型分为患者编码、预训练和微调三大部分。

图3:RAREMed模型图
患者表示(Encoder)
为了更全面地捕捉患者的病情信息,给定患者的疾病\(\mathbf{d}\)、手术\(\mathbf{p}\)等输入,我们将这些编码连接起来作为一个统一的序列输入给transformer模型:
其中[CLS]和[SEP]是特殊编码,分别表示序列开端符和分隔符。\(\oplus\)表示序列连接符号。患者的疾病和手术编码按照与患者此次住院的重要性排序,重要性在数据集中已经由专业医生完成标注。
在此基础上,我们设计了三个嵌入层,其中,符号嵌入层(Token Embedding)表示每个token的语义,相关性嵌入层(Relevance Embedding)用于编码每个token的重要性,只与位置相关,分类嵌入层(Segment Embedding)用于编码输入token的类别,标识每个token属于疾病还是手术。
最后,这些embedding经过一个transformer编码器,生成病人表示,采用[CLS]符号的输出层编码:
预训练(Pre-training)
为了增强模型的表示学习能力,我们针对药物推荐任务设计了两种预训练任务:
Task #1: 序列匹配预测 Sequence Matching Prediction (SMP) :SMP任务的目标是使模型能够预测输入的疾病和手术两个序列是否属于同一个病人。我们为每个真实病人的(\(\mathbf{d_i}\), \(\mathbf{p_i}\))正样本对匹配一个负样本对(\(\mathbf{d_i}\), \(\mathbf{p_j}\)),其中\(\mathbf{p_j}\)来自随机采样的另一个患者的手术序列。然后,我们使用Binary Cross-Entropy (BCE) loss来优化模型参数:
其中\(\hat{y}_i=\sigma(W_1\mathbf{r}_i + b_1)\in\mathcal{R}\) 表示正样本对的预测概率,\(\hat{y}_j\)表示负样本对的预测概率。这里,\(\sigma\)表示sigmoid函数。\(W_1\in\mathbb{R}^{dim}\)和\(b_1\in\mathbb{R}\)是可训练的参数。
**Task #2: 自重构 Self Reconstruction (SR): ** SR任务的目标是使模型可以从病人表示中重构出输入序列。这个任务会鼓励RAREMed捕捉和保存输入编码中尽可能多的信息。损失函数定义如下:
其中\(\hat{\mathbf{c}} = \sigma(W_2\mathbf{r}+b_2)\in[0,1]^{|\mathcal{D}|+|\mathcal{P}|}\)表示由RAREMed重构的所有疾病和手术的概率,\(W_2\in\mathbb{R}^{(|\mathcal{D}|+|\mathcal{P}|)\times dim}\)和\(b_2\in\mathbb{R}^{|\mathcal{D}|+|\mathcal{P}|}\)是可学习的参数。在这里,\(\mathbf{c}\in\{0,1\}^{|\mathcal{D}|+|\mathcal{P}|}\)表示真实标签。仅当输入序列中出现相应的标签时,才将\(\mathbf{c}_j\)设置为1。
微调和推理(Fine-tune and Inference)
经过预训练之后,我们在药物推荐任务上对RAREMed进行微调,以使其适应下游的药物推荐任务。为了预测药物,我们集成了一个多标签分类层,并利用患者表示作为输入:
where \(\hat{\mathbf{o}}\in[0,1]^{|\mathcal{M}|}\)为药物被推荐的概率。\(W_3\in\mathbb{R}^{|\mathcal{M}|\times dim}\)和\(b_3\in\mathbb{R}^{|\mathcal{M}|}\)是可学习参数。
我们使用如下损失函数对模型参数进行优化:
其中𝛼和𝛽是平衡不同损失贡献的超参数。
在推理过程中,我们向患者推荐概率大于阈值\(\delta = 0.5\)的药物。因此,最终的推荐药物集\(\hat{\mathcal{Y}}\)可以定义为:
实验
实验设置
我们采用MIMIC-III和MIMIC-IV两个EHR数据集,并仿照前人的工作对数据进行的筛选和处理。

我们选取Jaccard、PRAUC、F1、DDI rate和#Med作为评测指标,评价各模型的推荐精度和安全性。其中Jaccard、PRAUC、F1越高,表示药物推荐越准确;DDI rate越低,表示药物相互作用越少,推荐结果越安全;而#Med越接近医生开药的平均药物数量,说明模型预测越合理。
实验结果
- RAREMed比现有药物推荐方法准确性更高、安全性更好。

-
RAREMed可以产生更公平的药物推荐结果,对罕见病病人的药物推荐精度显著高于现有模型

-
预训练任务、统一的序列编码、设计的两个额外的嵌入层都对推荐精确度和公平性有正向的影响

- 超参数对RAREMed推荐结果的影响
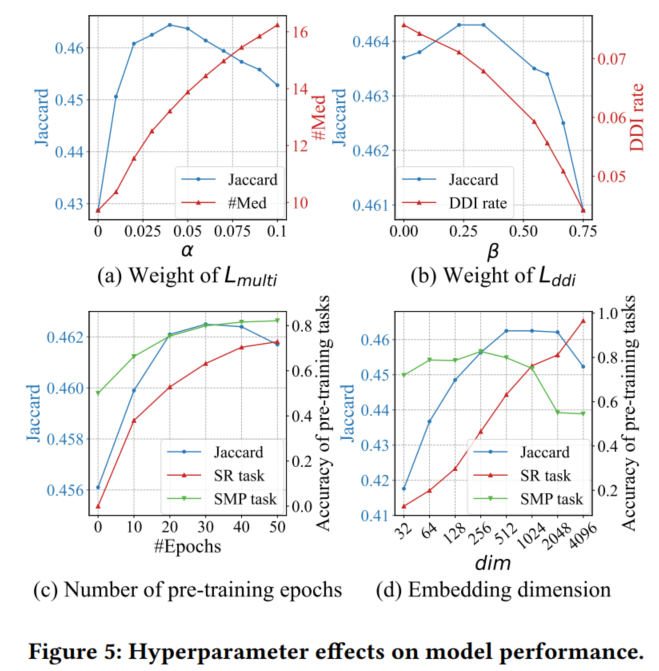
标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
