首页 > 极客资料 博客日记
大数据资产管理架构设计篇-来自《数据资产管理核心技术与应用》一书的权威讲解
2024-10-11 16:00:07极客资料围观18次
数据资产管理是一项系统而复杂的工程,涉及到元数据、数据血缘、数据质量、数据服务、数据监控、数据安全、数据权限等众多方面,为了更高效的管理好数据资产,因此在很多大型的企业或者组织中,通常会构建一个数据资产管理平台来管理这些各种各样的数据资产,数据资产管理平台通常会包含如下功能: 关注清哥聊技术公众号,获取更多权威技术文章。
- 元数据:主要负责元数据的维护和查看,让元数据成为数据资产的一个“电子目录”,方便外部用户查看和检索其需要的数据是存储在哪个数据库以及哪个表的哪个字段中,也方便外部用户知道数据资产中每个数据库、表、字段的具体含义。
- 数据血缘:主要负责数据与数据之间的血缘关系跟踪,以方便用户在使用数据时,能快速知道数据的处理过程以及来龙去脉。
- 数据质量:主要负责数据质量的监控与告警,当数据质量出现问题时,能够快速让相关的人员知道,数据质量的监控是持续提高数据质量的关键所在,也是数据资产持续优化、改进、提高质量的关键。
- 数据服务:主要负责数据服务的管理,包括服务的创建、开发、发布上线以及被业务请求调用。数据服务是数据对外使用和产生价值的最常见方式之一,所以数据服务的管理与维护至关重要。
- 数据监控:主要负责数据链路、数据任务、数据处理资源、数据处理结果等的监控与告警,当数据出现问题时,能够通过监控与告警,让数据问题得到及时快速的解决。
- 数据安全:主要负责数据安全的管理,数据安全是数据资产管理中最重要的环节,也是数据资产管理的基础。通过评估数据的安全风险、制定数据安全管理的规章制度、对数据进行安全级别的分类,完善数据安全管理相关规范文档,保证数据是被合法合规、安全地获取、处理、存储以及使用
- 数据权限:主要负责数据权限的分配与管理,通过数据权限的控制,能够更好的去保护数据资产中的隐私信息和敏感信息。
- 数据冗余:一般指的是由于数据没有进行统一的管理,导致很多不同的平台或者系统都存储了相同的数据,特别是对于一些很多业务或者系统都需要共用的数据。
- 数据孤岛和数据分散:由于数据没有进行统一的集中式管理,所以数据很容易分散在不同的系统中并且容易产生数据孤岛。
- 数据口径无法统一:每个业务系统都有自己的数据管理和分析,导致数据计算的口径会存在不一致,这样的话,就导致在做数据决策时,不知道到底以那一份数据口径为准。
1、数据资产的架构设计
数据资产架构是指为了让数据资产管理更加信息化、高效化、平台化而构建的一套系统架构。通常来说数据资产架构会包含如下的一些方面:
1.1、数据获取层
数据获取层通常又叫数据采集层,主要负责从各种不同的数据源中去获取数据,如下图
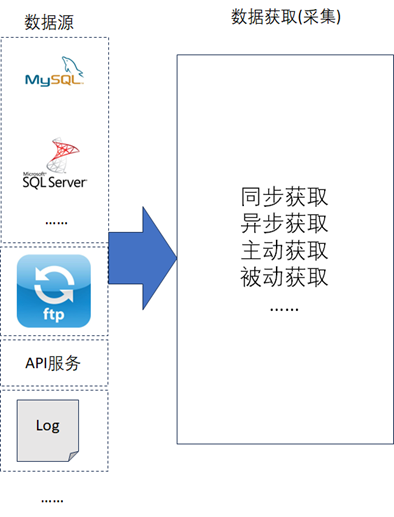
数据获取层在获取数据时会存在多种不同类型的数据源,从每一种类型的数据源中获取数据的方式是不一样的,所以在数据获取层的架构设计中,需要考虑兼容多种不同数据源,并且在出现新的类型的数据源时,需要能够支持花最小的代码改造代价去做扩展。所以通常建议数据资产架构设计中数据获取层的架构可以设计成即插即用的插件类型,如下图所示,这种设计方式可以很好的解决数据源的可扩展性的问题。
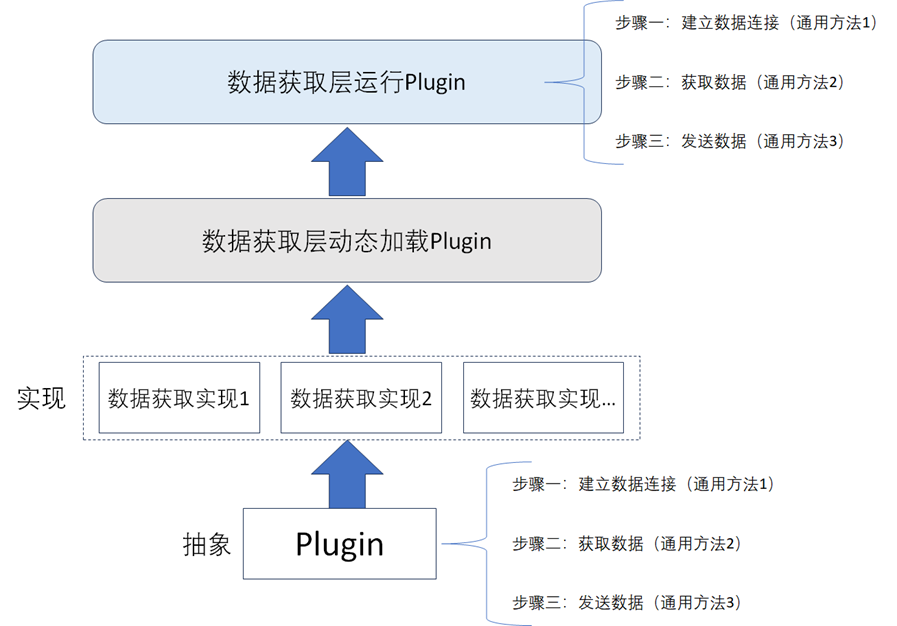
从图中可以看到
- 设计了一个抽象类型的插件,这个插件中包含了从数据源中获取数据时需要的三个基本的步骤,也是需要实现的三个通用的底层方法。
- 数据资产管理平台的数据获取层在加载完实现好的插件后,便可以去按照步骤顺序去调用已经实现好的三个通用的方法来获取数据。
1.2、数据处理层
数据处理层主要负责将从不同数据源中获取到的数据做处理,是整个数据资产架构的核心部分,数据处理的方式通常包含实时和离线两种方式,通常情况下数据处理层需要完成的主要功能如下图所示。
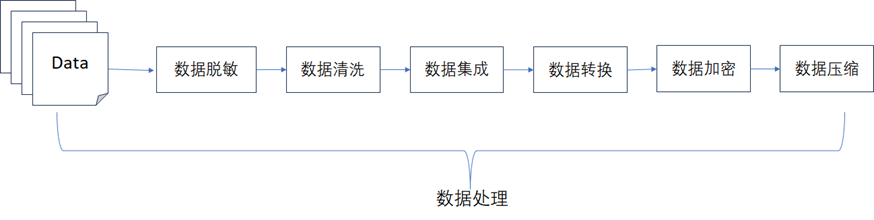
- 数据脱敏:对原始数据中的敏感信息进行脱敏操作,防止隐私数据被泄露。
- 数据清洗:去除原始数据中的无效数据、重复数据等,以提供数据处理的质量。
- 数据集成:将同时来自于多个不同的数据源的数据进行整合形成统一的数据集。
- 数据转换:对原始数据进行转换(比如进行统一的格式转换、类型转换等),以满足数据仓库或者数据湖的存储设计。
- 数据加密:对一些隐私数据进行加密,方便数据存储后确保数据的安全性,对隐私数据进行保护。
- 数据压缩:为了节约存储成本,在数据存储前,对数据进行压缩处理,在不丢失数据的前提下,减小数据的存储大小。
在大数据处理中,最常用的架构方式就是Lambda架构和Kappa架构,如下所示
- Lambda架构:是一套强调将离线和实时任务分开处理的大数据处理架构,如下图所示
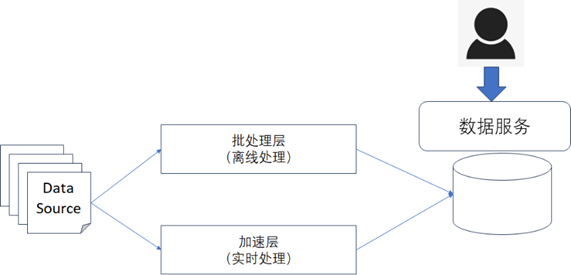
从图中可以看到Lambda架构是将离线处理和实时处理分开进行维护的,这就意味着需要开发和维护两套不同的数据处理代码,系统的复杂度很高,管理和维护的成本也很高。
- Kappa架构:是一套将离线和实时数据处理整合在一起的大数据处理架构,如下图所示
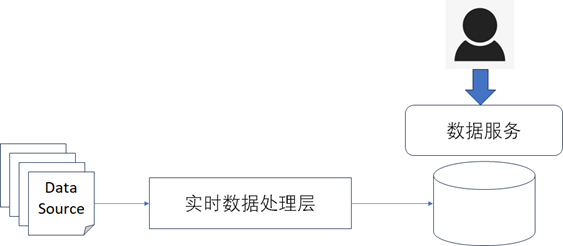
Kappa架构其实可以看成是Lambda架构的优化和改进,在Kappa架构中实时任务需要承担全部数据的处理,会让实时任务处理的压力较大,但是Kappa架构将实时代码和离线代码进行了统一,方便了代码进行管理和维护也让数据的口径保持了统一,同时也降低了维护两套代码的工作量。
相比于Lambda架构,Kappa架构最大的问题在于一旦需要对历史数据进行重新处理,那么Kappa架构将难以实现,因为Kappa架构通常所使用的都是实时流处理的技术组件,比如像Flink等,但是如果做历史数据处理时,可能像Flink这样的技术组件就难以胜任,而擅长做离线数据处理的类似Spark这样的技术组件会更加适合,但是Flink的代码和Spark的代码通常是无法做共用的。
从对Lambda架构和Kappa架构的对比分析来看,两者各有优点,也有缺点,在实际应用当中,可能还需要同时结合这两种架构的优缺点来设计最符合自身业务和需求的数据处理架构。通常建议如下:
- Lambda架构和Kappa架构 可以同时存在,对于经常有需要做历史数据处理的数据类型,建议保留为Lambda架构。
- 对于几乎不需要做历史数据处理的数据类型,建议尽可能走Kappa架构来实现。
1.3、数据存储层
数据存储层主要负责各种类型的数据的存储,在架构设计时,还需要综合考虑如下问题来制定数据存储的架构和策略。
- 数据查询的性能:比如查询的响应时间、数据访问的吞吐量、查询的TPS等。
- 数据的冷热程度:根据数据的冷热程度,对数据进行划分,对于冷热程度不一样的数据,可以分开存储,通常对于冷数据,可以采用一些成本更低的存储介质来进行存储,方便节省数据存储的成本。
数据存储的技术方案可以有很多选型,如下所示,通常需要根据实际的业务需要来进行综合的选择。
- 传统数据仓库存储:传统的数据仓库的代表就是Hive,可以负责海量数据的存储和基于Hive做数据分析和挖掘,但是Hive 数仓存在以下不足
- 通常只能存储结构化的数据或者经过处理后生成的结构化数据。
- Hive数仓中更新数据的能力较弱,一般只能做数据的批量插入。
- 数据湖存储:数据湖是在传统数仓上发展而来的,也是可以完成海量数据的存储,相比于数据仓库,数据湖具有如下优势:
- 数据湖可以存储结构化数据,也可以存储半结构化数据和非结构化数据。
- 数据湖中可以直接存储没有经过任何处理的原始数据,也可以支持直接对原始数据做分析。
- 数据湖中支持数据快速做更新、删除等操作。
- 更适合做机器学习、探索性分析、数据价值挖掘等。
在开源社区中,常见的数据湖有Hudi、Delta Lake、Iceberg等。
- 分布式数据库存储:分布式数据库存储一般用于存储对于实时查询要求较高或者要求实时做OLAP数据分析的数据,在开源社区中,常见的分布式数据库有Apache Doris(可以通过官网https://doris.apache.org/了解更多关于Apache Doris的介绍)、Apache Druid(可以通过官网https://druid.apache.org/了解更多关于Apache Druid的介绍)等。
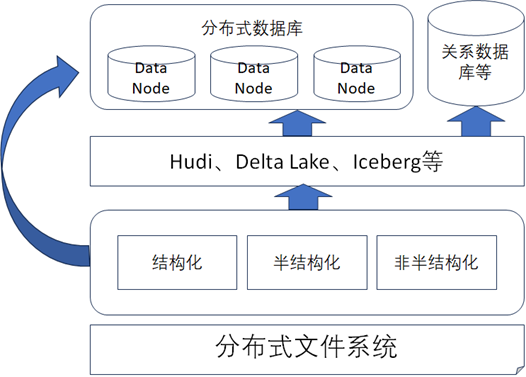
通过以上分析,数据存储层的架构设计通常建议设计成当前最为流行的湖仓一体的架构,并且针对特殊的业务场景,可以引入一些分布式数据库或者关系型数据库进行辅助,如下图所示。
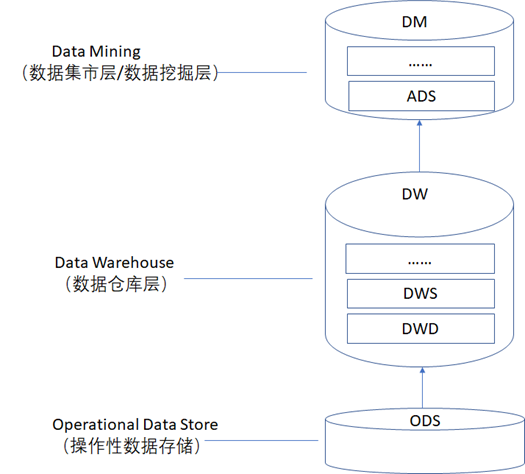
数据存储层在存储数据时,通常还会对数据进行分层存储,数据分层的架构实现方案通常如下图所示,数据分层主要是为了
- 对数据进行模块化设计来达到数据之间解耦的目的,数据通过分层可以将一些非常复杂的数据解耦为很多个独立的数据块,每一层完成特定的数据处理,便于开发、维护以及让数据可以被更好的复用。
- 让数据的可扩展性更强,当数据业务发生需求变化时,只需要调整响应数据层的数据处理逻辑,避免了整个数据都需要从原始数据(也就是图中的ODS层的数据)来重新计算,节省了开发和数据计算的资源成本。
- 让数据的查询性能更快,在大数据中,由于存在海量的数据,如果全部从原始数据(也就是图中的ODS层的数据)中来查询业务需要的数据结果,需要扫描的数据量会非常大,将数据分层后,可以优化数据的查询路径,减少数据扫描的时间以达到提高数据查询性能的目的。
1.4、数据管理层
数据管理层主要负责对数据进行分类、标识以及管理,主要会包含元数据管理、数据血缘跟踪管理、数据质量管理、数据权限和安全管理、数据监控和告警管理等,其总体的实现架构图如下图所示。
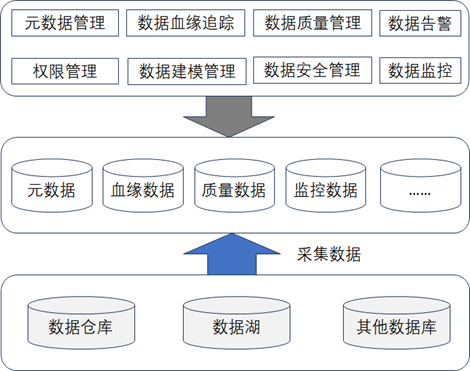
数据管理层的技术核心就是元数据、血缘数据、质量数据、监控数据等采集获取,我们在 清华大学出版社出版的 《数据资产管理核心技术与应用》一书的前面的章节中已经有过很具体的描述,在拿到这些数据后,数据管理层主要要实现的功能就是把这些数据做集成并且展示到数据资产管理平台中,数据管理层是数据资产管理的核心。
1.5、数据分析层
在数据分析层的架构设计中,主要包含如下两个部分:
- 数据分析工具的选择:随着大数据分析技术的发展,诞生了很多和数据分析相关的BI工具,常见的BI分析工具的相关介绍如下表所示:
|
BI 工具名称 |
描述 |
适用的场景 |
|
Power BI |
是由微软推出的一款BI数据分析工具 |
成本较高,通常适合于微软云相关的服务中使用 |
|
Pentaho |
开源的BI分析工具,具有数据整合、报表生成和数据可视化等功能 |
开源产品。适合于自己有部署和运维能力的团队进行使用 |
|
Quick BI
|
是阿里云推出的一款BI数据分析工具 |
由于是阿里云推出,所以通常只适合于阿里云中使用。 |
|
FineBI |
是由帆软推出的一款BI数据分析工具 |
商业软件,一般需要购买,通常适用于政府或者企事业单位使。 |
在选择BI的数据分析工具时,一般建议结合自身的业务需求、使用成本、管理维护成本等多个方面来综合考虑,然后再选择最合适的BI工具。
- 数据的加工与处理:这里的数据加工与处理主要是指数据分析需要做的数据预加工与处理,以便数据分析工具能快速得到自己想要的数据。在大数据中,由于是海量的数据,所以在数据分析时,BI分析工具通常不会直接去从海量的原始数据中直接做分析。
通过如上两点的分析,数据分析层的整体架构设计通常如下图所示。
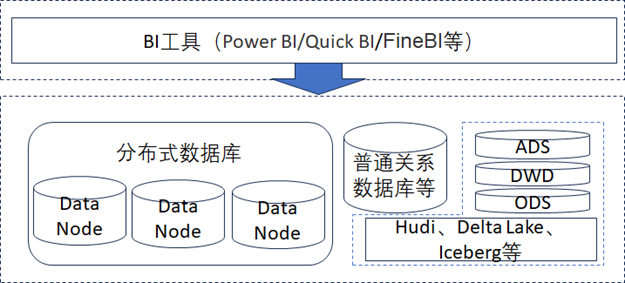
- 数据分析时,对于实时性要求较高的数据,通常会存储在分布式数据库中,不做太多的预处理,让BI工具直接去查询和访问,这样可以保证整个数据分析链路的实时性。
- 对于实时性要求不高的数据,可以每天通过离线的方式进行处理,通常会从数据仓库或者数据湖中,每天离线对数据做预处理,处理的结果数据可以根据数据量的大小选择放入普通关系型数据还是放入数据仓库或者数据湖的ADS应用层来供BI工具做分析使用,甚至数据湖或者数据仓库的DWD数据明细层或者DWS数据轻度汇总层也可以开放给BI数据分析工具直接做分析。
1.6、数据服务层
数据服务层通常是让数据对外提供服务,让数据可以服务于业务,并且负责对数据服务进行管理,数据服务层通常的架构实现如下图所示,数据服务的具体技术实现细节可以参考清华大学出版社出版的《数据资产管理核心技术与应用》一书的第六章。
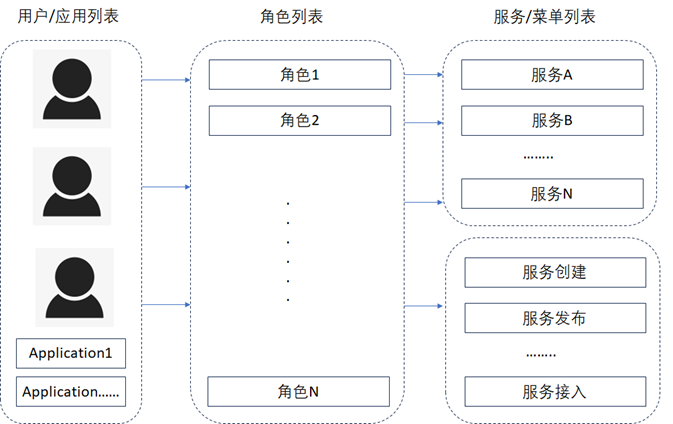
数据服务层在设计时,通常需要包括服务创建、服务发布,服务接入、服务降级、服务熔断、服务监控以及权限管理等模块,对于服务访问的权限管理通常建议也可以采用基于角色的访问控制 (RBAC)来实现,如下图所示。
- 一个角色可以拥有一个或者多个不同服务,也可以拥有一个或者多个不同的菜单。
- 角色可以赋予给用户,也可以赋予给调用服务的业务需求的上游。
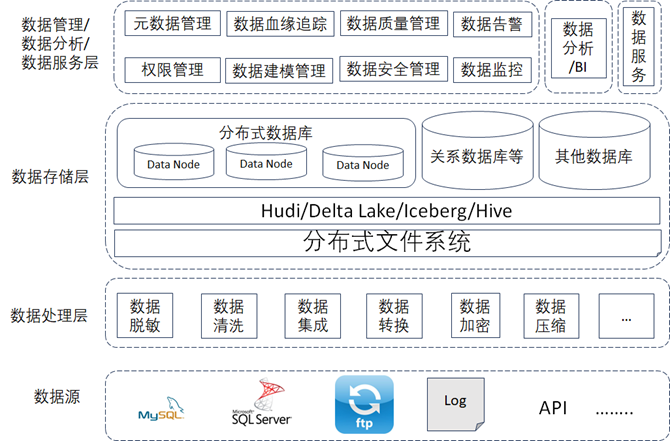
通过对每一层做架构分析与设计后,得到最终如下图所示的数据资产架构图,这是大数据处理中最常见的架构设计方案,解决了数据的可扩展性以及对于不管什么类型或者什么什么格式的数据,都可以做数据处理、存储以及分析。
《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,全书共分10章,第1章主要让读者认识数据资产,了解数据资产相关的基础概念,以及数据资产的发展情况。第2~8章主要介绍大数据时代数据资产管理所涉及的核心技术,内容包括元数据的采集与存储、数据血缘、数据质量、数据监控与告警、数据服务、数据权限与安全、数据资产管理架构等。第9~10章主要从实战的角度介绍数据资产管理技术的应用实践,包括如何对元数据进行管理以发挥出数据资产的更大潜力,以及如何对数据进行建模以挖掘出数据中更大的价值。
标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
