首页 > 极客资料 博客日记
【赵渝强老师】基于大数据组件的平台架构
2024-09-28 13:00:03极客资料围观17次

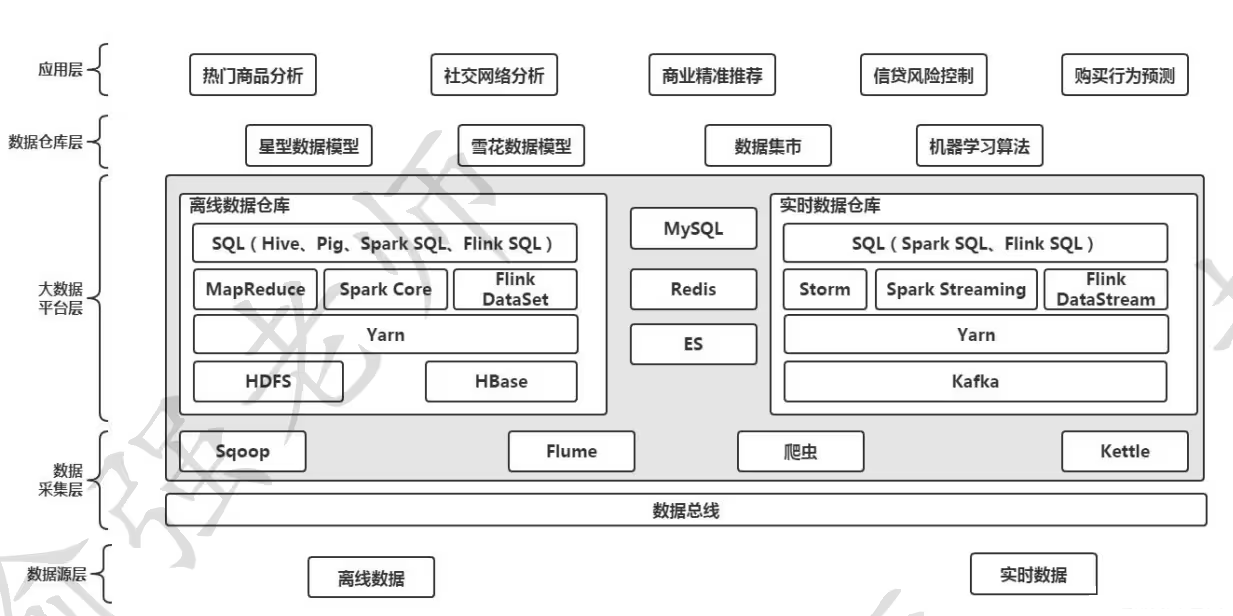
在了解了大数据各个生态圈所包含的组件及其功能特性后,就可以利用这些组件来搭建一个大数据平台从而实现数据的存储和数据的计算。下图展示了大数据平台的整体架构。
视频讲解如下:
视频讲解如下:
| 大数据平台的Lambda架构 |
|---|
| 大数据平台的Kappa架构 |
|---|
大数据平台的总体架构可以分为五层,分别是:数据源层、数据采集层、大数据平台层、数据仓库层和应用层。
一、数据源层
数据源层的主要功能是负责提供各种需要的业务数据,例如:用户订单是数据、交易数据、系统的日志数据等等,总之把能够提供的数据都可以称之为数据源。尽管数据源的种类多种多样,在大数据平台体系中可以把它们划分成两大类,即:离线数据源和实时数据源。顾名思义,离线数据源用于大数据离线计算中;而实时数据源用于大数据实时计算中。
二、数据采集层
有了底层数据源的数据,就需要使用ETL工具完成数据的采集、转换和加载。在Hadoop体系中就提供了这样的组件。例如可以使用Sqoop完成大数据平台与关系型数据库的数据交换;使用Flume完成对日志数据的采集。除了大数据平台体系本身提供的这些组件外,爬虫也是一个典型的数据采集方式。当然也可以使用第三方的数据采集工具,例如:DataX和CDC完成数据的采集工作。
为了解决数据源层和数据采集层之间的耦合度,可以在这两层之间加入数据总线。数据总线并不是必须的,它的引入只是为了在进行系统架构设计的时候,降低层与层之间的耦合。
三、大数据平台层
这是整个大数据体系中最核心的一层用于完成大数据的存储和大数据的计算。由于大数据平台可以看成数据仓库的一种实现方式,进而又可以分为离线数据仓库和实时数据仓库。下面分别进行介绍。
3.1 基于大数据技术的离线数据仓库实现方式
底层的数据采集层得到数据后,通常可以存储在HDFS或者HBase中。然后由离线计算引擎,如:MapReduce、Spark Core、Flink DataSet完成离线数据的分析与处理。为了能够在平台上对各种计算引擎进行统一的管理和调度,可以把这些计算引擎都运行在Yarn之上;接下来就可以使用Java程序或者Scala程序来完成数据的分析与处理。为了简化应用的开发,在大数据平台体系中,也支持使用SQL语句的方式来处理数据,即:提供了各种数据分析引擎,例如:Hadoop体系中的Hive,其默认的行为是Hive on MapReduce。这样就可以在Hive中书写标准的SQL,从而由Hive的引擎将其转换成MapReduce,进而运行在Yarn之上来处理大数据。常见的大数据分析引擎除了Hive,还有Spark SQL和Flink SQL。
3.2 基于大数据技术的实时数据仓库实现方式
底层的数据采集层得到实时数据后,为了进行数据的持久化同时保证数据的可靠性,可以将其采集的数据存入消息系统Kafka;进而由各种实时计算引擎,如:Storm、Spark Stream和Flink DataStream进行处理。与离线数据仓库一样,可以把这些计算引擎运行在Yarn之上,同时支持SQL语句的方式对实时数据进行处理。
离线数据仓库和实时数据仓库在实现的过程中,可能会用到一些公共的组件,例如:使用MySQL存储的元信息、使用Redis进行缓存,包括使用ElasticSearch(简称ES)完成数据的搜索等等。
四、数据仓库层
有了大数据平台层的支持就可以进一步地搭建数据仓库层了。而在搭建数据仓库模型的时候,又可以基于星型模型或者雪花模型进行搭建。前面曾经提到的数据集市和机器学习的算法也可以划归到这一层中。
五、应用层
有了数据仓库层的各种数据模型和数据后,就可以基于这些模型和数据去实现各种各样的应用场景了。例如:电商中的热门商品分析、图计算中的社交网络分析、推荐系统的实现、风险控制,以及行为预测等等。
标签:
相关文章
最新发布
- Nuxt.js 应用中的 prerender:routes 事件钩子详解
- 【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
- 六、Spring Boot集成Spring Security之前后分离认证流程最佳方案
- 《JVM第7课》堆区
- .NET 8 高性能跨平台图像处理库 ImageSharp
- 还在为慢速数据传输苦恼?Linux 零拷贝技术来帮你!
- 刚毕业,去做边缘业务,还有救吗?
- 如何避免 HttpClient 丢失请求头:通过 HttpRequestMessage 解决并优化
- 让性能提升56%的Vue3.5响应式重构之“版本计数”
点击排行
本站推荐
